|
|
||
CCIE R&S v4.0 理论 当前位置: 首页→CCIE资料库→CCIE R&S v4.0 理论→MPLS/MPLS_VPN MPLS / MPLS_VPN
文档下载: 目录 MPLS
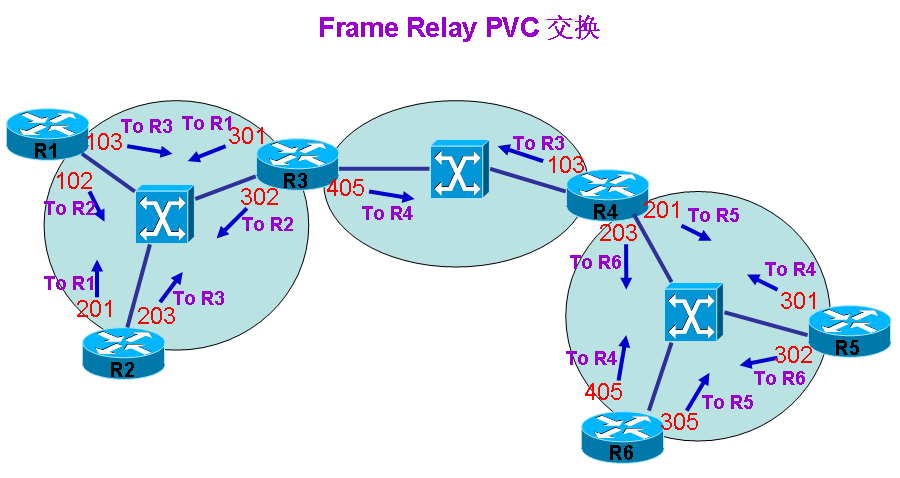
MPLS 非IP包头交换过程 1.帧中继 PVC 交换方式
在我们现有的网络当中,IP数据包网络占绝大部分,这样的IP数据包网络,在网络设备传递数据包时,是根据数据包的IP包头信息进行交换的,也就是网络设备根据包头中的目标IP地址,来决定从哪个接口转发出去。所以在数据包当中,指导设备正确转发数据包的就是IP地址信息,而IP地址只是数据包的一个标识而已。既然数据包的包头信息能够指导设备正确转发,那数据包的包头只要能够被设备正确接受,就能够做出正确的转发决策,正因为如此,网络就产生了其它不同于IP数据包交换方式,比如我们应当熟悉的帧中继网络(Frame Relay)。在帧中继网络中,很明显,帧中继设备(帧中继交换机)在决定数据包该从哪个接口被发出去时,查看的就是包头PVC号码,而不是IP地址,这个PVC号码,对于帧中继设备来说,就关系到这个数据包应该从哪个接口被转发出去。如上图所示,在帧中继交换机中,只关系数据包的PVC号码是多少,只要看到这个号码,就知道该从哪个接口出去,等数据包到了下一台交换机之后,下一台交换机也做同样的操作,即查看数据包的PVC号码后就从相应接口发出去,但是不同数据包的PVC号码肯定应该是不一样的,因为同一个PVC号码,对于交换机来说,都应该从同一个接口出去。所以说一台交换机上的每个接口相关联的PVC号码都是不一样的。但是,这台交换机用过的PVC号码,到了下一台交换机之后,还是可以使用的,因为前面一台交换机根据某个PVC号码对数据包转发之后,自己再根据数据包的PVC进行转发,与前面是不冲突的,因为是各自关联好的。从这里也可以想象出,一个数据包经过一台帧中继交换机之后,到了下面一台,数据包的PVC是应该被设备进行重新改写才交换的,因为不可能一个PVC经过N台交换机还是一样的。所以可以得出一个理论就是,帧中继数据包的包头信息(即PVC号码)仅一跳有效,也就是本地有效,不同交换机之间,包头信息可重复,在这里用过的PVC号码,在别的交换机上也可能出现一样的,只要保证在单台交换机唯一就可以了,所以每次经过一个交换机之后,需要重新改写包头信息。
2.非IP数字包头交换方式 下面来看一下既不是IP数据包交换,也不是帧中继交换的网络,那么这样的网络给数据包写上什么样的包头来指导设备正确转发呢?就写一个号码而已,我们暂且称它为非IP数字包头交换。在这样的网络中,设备看到包头中的这个数字,就知道该从哪个接口转发出去,每台都是一样的。这种网络跟帧中继交换相同的是设备也是查看一个号码,而不同的是,一个数据包写上一个号码之后,永远都不会被任何设备改写,直接传到目的地为止,可想而知,网络中任意两台主机之间,他们的号码必须是唯一的,因为每台交换机都要根据这个号码来做出转发,如果两个数据包的号码相同,那么所有的交换机都做同样的转发,结果就导致这些数据包被发到同一台设备。这样的数字网络,全球中,每两点之间仅有一个号码表示,第一个点的数据包头写上此号码,必定是发到第二个点,不可能发送到第三个点,因为第一个点和第三个点,会使用另外一个号码,所以此号码为两点唯一,网络设备中有每两点(即每个号码)的出口信息,收到任何一个包,都能不看IP地址而根据此号码选择从相应接口发出去,每台设备执行相同的过程,即可完成任意两点间的传输。此交换方式其实并没有在计算机网络中应用,但是我们使用的电话网络,就是这种交换方式,即任何两台电话之间打电话,号码唯一,不可能有相同号码,如果你拨打电话,别人也拨一个电话号码,你们拨的号码如果是一样的,那肯定就打到同一个人那里去了。所以要实现此交换方式,网络中所有设备需要计算出任意两个点之间的号码,每一个号码都是唯一的,不可重复,与到目的地的相应出口作对应,生成转发表。但是如果全球计算机网络使用这样的方式,那就是任何一台设备为任何一台主机计算路径时,都要所有全球的设备共同参与,如果不全部都参与,就可能和没参与的计算出重复号码,可想而知工作量之庞大。 3.交换方式总结 以上两种交换方式,都是在不看IP地址(IP包头),只看号码的情况下,做出的交换选择。 可以仔细想一下,在使用帧中继交换时,因为一个PVC号码只要保证单台设备不重复就可以了,这个号码跟接口是关联着的,也就是说一个数据包写上的PVC号码,这个PVC号码的范围只要比交换机的接口多就行,比如范围是1024,所以帧中继交换的包头,号码不是很庞大,也就是说包头并不是很长。而非IP包交换的网络中,因为每两点之间都要有独立的号码,所以如果网络中有10亿个点,那么这个号码的范围就应该比10亿还要大,所以非IP包交换,数据包头肯定要比帧中继的包头大。 但是从结论中,我们能不能说哪个好,哪个不好呢?当然不能,因为帧中继的包头虽然比非IP的包头要小,但是每经过一台设备都要重新改写,也就是说帧中继网络中,设备都在不停地为每个数据包改写PVC号码,这也是巨大的工作量啊。而非IP包头虽然要大一些,但是这个号码写好之后,就永远不会再变了,只要中间的设备看到号码直接转发就行,不用改写了。 4.MPLS(多协议标签交换) 在使用IP包交换网络的时候,人们总是认为设备要根据IP地址查路由表做出转发决定,觉得这样很耗时,总想着寻找一种新的交换技术来代替IP包交换。最初就考虑使用数字号码的方式来代替IP地址,从上面介绍的交换方式中,由于第二种非IP包交换技术,需要在网络中对任意两点计算出一个全球唯一的号码,因为一个号码即代表了两个点之间的传输,如果其它的点之间的号码和别人出现重复,那么数据的走向也就会发生错误。当前没有研发出协议敢保证计算出任意两点的号码一定是唯一的。
在帧中继的交换中,只要保证每个网段(每台交换机)之间的PVC号码唯一即可,因为经过每个网段(每个交换机)号码都会重新修改。此交换方式也可避免设备检查数据包的IP地址来作做转发决定。(但也不要忘记,这种交换方式的弊端,在似乎节省了时间的同时,其实也浪费了许多时间。) 而当前人们认为效率比较高的MPLS(多协议标签交换)方式,它的数据交换思想则倾向帧中继的交换方式,即认为设备在查看IP地址之后做出转发决定,会比较慢,会耗更多时间,则给数据包写上了额外的号码,根据此号码而不看IP地址,便能找出相应出口从而转发出去,这正是标签交换,而MPLS称此额外的号码为标签。在此可以看出,MPLS的交换号码(标签)并不是全球唯一,只是每个网段唯一,或者说是每跳唯一,所以,经过一跳之后,此号码对下一跳设备毫无意义,经过一跳之后,此号码要修改成对下一跳有意义的号码,让其根据号码做出转发决定。由此可见,MPLS的标签交换,是每跳都会改写标签,因为根据标签,便能够做出转发决定,所以省略了查看IP地址的过程,被人们认为比IP交换要快。 而MPLS根据自己的标签交换,需要给数据包先写上自己的标签,然后设备才能查看标签之后就转发,此标签是需要在原有的数据包的基础上加进去的,并没有将以前的包头删除,MPLS的标签加在了第二层帧的帧头之后,但又在第三层数据包的包头之前,而MPLS不管是什么协议的数据包,不管以前的包头是什么,都能够在包中加入对自己有利的标签,所以称MPLS交换为多协议标签交换。 MPLS优势:
1.(不正确的理由):因为IP在路由当中,总是根据目的地址在路由表中查找目标网段,并且逐条匹配最优路径,速度慢。 2.MPLS只根据数据包顶部标签来查找并转发,速度快。 结论:由于现在设备采用ASIC(专用集成电路)交换,所以速度并不慢,而MPLS借签了帧中继交换方式,在数据包每经过一台设备时,都要重新封装,所以MPLS在速度上,并不是优势。 但MPLS可以给数据包加上标签,以做流量控制,这是优势。MPLS还可以承载各种协议,如IPv4,IPv6, 以太网,HDLC,PPP,以及其它第二层帧。 注:MPLS在骨干网中传输任意第二层帧的特征被称为MPLS的任意传输(AToM)。 MPLS中的BGP
BGP在决定一个数据包该如何被转发出去,是通过查找IP地址在路由表中的下一跳,有时不能避免这下一跳不是跟自己直连的,但是BGP只要知道如何到达那个下一跳即可,所以BGP路由的下一跳,也许自己不清楚,但是只要IGP的路由能帮助自己到达下一跳就行。在大型的核心网络中,我们完全可以设计出网络这边的BGP路由器,它的下一跳在网络那边,那么如何到达网络那边的下一跳,中间就可以使用IGP去完成,只要中间的设备能够帮助BGP到达最终下一跳地址就足够了,所以这样的网络,需要BGP协议的只是网络的边缘路由器,而中间的路由器,只要做一件事,那就是帮BGP找下一跳,就不用启用BGP了,这就大大节省了系统资源。而MPLS的标签交换,就可以用在这样的网络中,来为BGP寻找下一跳,也就是MPLS只要为BGP路由的下一跳打上标签,能够帮助BGP找到下一跳,那么其它的问题,都不是问题,其它的路由,BGP就能够自己完成。 略:MPLS流量工程,路径是由首端路由器指定的,所以又称为基于源的路由。 思科MPLS历史 最初Cisco在IP报文顶部加入标签时,称其为标记交换(tag switching),而标记,现在改叫标签了,为每个路由条目分配好标记并写进去,所以这就需要一张表来指导标记交换,称为转发信息库(TFIB),每一台标记交换路由器查看数据包入站的标记,并转为出站标记后发出去。 注:思科第一个支持标记交换的IOS就支持流量工程,就是资源预留协议(RSVP) MPLS标签
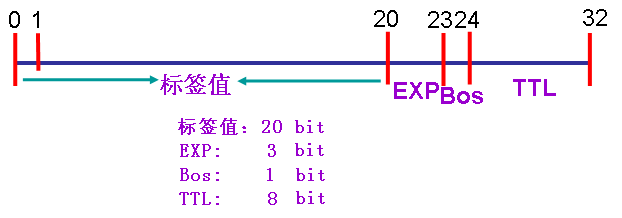
一个标签由32个bit组成 前20为标签值,范围从0到2的20次方减一,即1048575。 其中前16bit不能随便定义,有特定含义,从21到23bit共3位试验用(EXP),用于QOS。 第24比特是栈底Bos位,值为0,如果是栈底,就为1,标签栈中,标签数量没有限制。 从25到32共8个bit是TTL MPLS标签栈 MPLS路由器对数据包可能添加一个标签,也可能添加多个标签,这些标签集合起来叫做标签栈,第一个为顶部标签,最后一个为底部标签,中间数量可以无限,底部标签BOS总是1,否则就是0。而在数据包传输过程中,设备只根据第一个顶部标签来决定怎么转发。 有些情况是需要两个标签的,两个典型是MPLS VPN和AToM。MPLS VPN要用两个标签,是因为在骨干中传输时,用一个,等出了骨干,再用另外一个。 那么设备收到一个MPLS标签数据包时,又怎么知道这个数据包是要查IP路由表来决定转发呢,还是查标签表做出转发呢?那是因为标签是在第二层帧和第三层数据包之间,第二层会在数据链路层的协议字段写上新的值,以说明后面是一个带有MPLS标签的报文,所以设备能够做出正确的转发决策。 MPLS设备类型
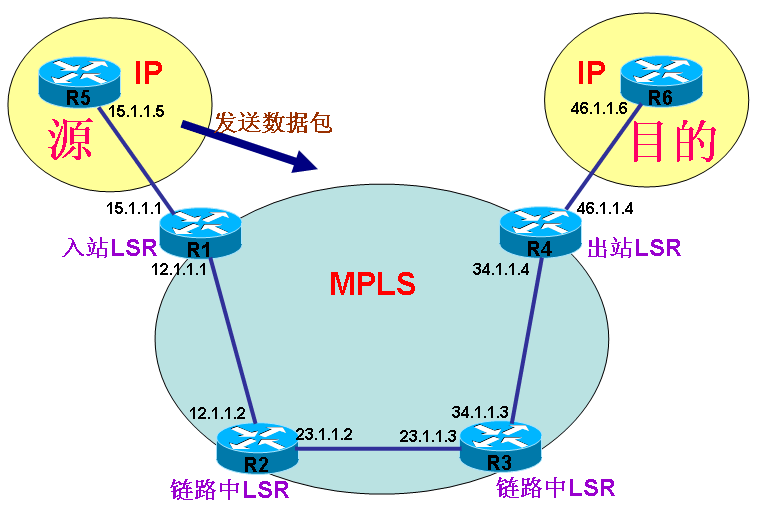
能够理解MPLS标签并根据标签转发数据包的路由器称为LSR 共有以下3种LSR: 入站LSR:接收没有标签的数据包,打上标签并发出 出站LSR:接收带有标签的数据包,移除标签,并发出,出站和入站LSR都是边缘LSR,所以它们同时连接了IP网络和MPLS网络。 链路中LSR:接收到带标签的数据包,对其进行操作,然后按正确的接口交换出去,所以链路中的LSR只进行标签转发。 LSR操作过程 LSR可以执行三种操作:提取,添加和交换 提取,即从标签栈的顶部移除一个或多个标签,移除全部标签是出站LSR必须做的。 添加,向报文添加标签,如果没有标签,就加新的,入站LSR必须做的。 交换,收到一个有标签的报文,用新的标签交换到顶部,再发出,是链路中的LSR做的。
注:在MPLS VPN中,入站和出站LSR就是提供商边缘PE,链路中LSR就是P,术语PE和P在没有运行MPLS VPN时,也可使用。 标签交换路径LSP LSP指的就是一个源到最终目的需要经过的路径,而在路径中,是要被修改多次标签,比如一个源到目的要分别被改为20,50,35,68,那么也可以简单认为这两个点之间的LSP是20-50-35-68。LSP是LSR在MPLS网络中转发标签数据后的产生的,是标签报文穿越MPLS网络的路径。LSP不需要记住,只需要知道是什么。LSP中第一台LSR就是入站LSR,最后一台就是出站LSR,之间的就是链路中LSR。 转发等价类(FEC) FEC可以认为是同一条路由,或者说是到达目标主机的路径是相同的,或者说是相同转发路径的数据流。同一个FEC,所有标签都相同,并不是拥有相同标签的报文都是同一个FEC,可能EXP值不同。报文属于哪个FEC,由入站LSR决定。FEC和LSP一样只需要知道是什么,不用记住。 注:一条FEC可以包含多个流,但不是一个流一个FEC,比如一台主机在看新浪的网页,这是一个流,又在看新浪的视频,这又是一个流,这两个流在新浪发给远程主机时,走的路径应该是相同的,所以一个FEC有多个流,但是每个流并没有属于单独的FEC。 MPLS标签交换过程
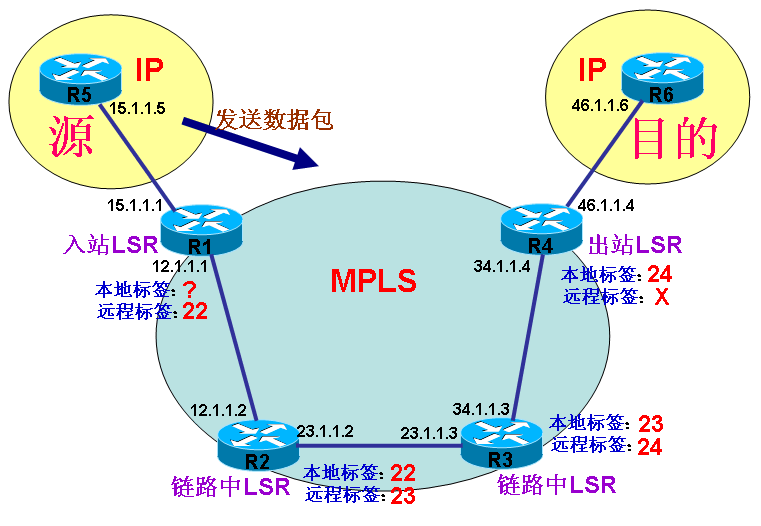
虽然一条路由可以打了多标签,但是中间的LSR只根据最顶部的标签便可以做出转发。但是,每台LSR的转发表里都会为一条路由显示两个标签,一个是本地标签,一个是远程标签,要显示两个标签,是因为一台LSR收到数据包之后,就查看它的顶部标签,如果这个标签是某一条相应的本地标签,那么就从相应的接口发出去,同时在发出去的时候,就将数据包的顶部标签改为与这个本地标签对应的远程标签,这是每台LSR在传输时都必须改的,因为改了相应的远程标签,对下一台LSR做出正确转发是有帮助的。所以LSR自己对于某一条路由,别人要给数据打上什么标签,它才能够正确转发,它是要明确告诉邻居的,最后结果就是每一台LSR都会将这个能指导自己做过正确转发的标签发给邻居,邻居就认定这个发来的标签是远程标签,那么邻居在发出去数据包之前,都会改成这个远程标签,最后就能按正确路径转发了。 上图中,比如R4要看到数据包中有标签24,就能够正确往R6(目的地)的方向发,那么这个标签24对于R4来说就是本地标签,那么别人LSR把数据包发给R4之前,就得为它打上标签24才发出来,所以R4就把这个标签24告诉给它的邻居R3,邻居LSR收到标签之后,就认为是远程标签,所以R3认为远程标签是24,而自己要拿到一个数据后,是什么标签自己就会改成24发给R4呢,自己也会产生一个本地标签,可以看到,R3产生的本地标签是23,数据包中只要顶部标签是23,就能够让R3把标签改成24后发给R4,所以R3也把这个标签23发给了邻居R2,邻居R2也同样为路由产生一个本地标签,是22,也就是说R2收到数据包标签为22的,就改成23,然后传给下一跳R3,最后R2也把对自己有利的标签22发给了R1,那么R1就知道发给R2之前,要把标签改成22,要不然R2就会转发出错的。 而因为R1是入站LSR,所以从外面发给它的数据包都是IP包,是不会有标签的,所以它是第一个向数据包加标签的LSR,可以看出只要它一开始往数据包里加上标签22后发给R2,最后就能一跳一跳地被发到R6,因为中间LSR的标签大家都是协商好的。在数据包到达R4时,R4就会将标签全部移除后发给R6,因为是进入IP网络,没有必要再打标签发出去。要说明的是,该为一个路由条目产生什么样的本地标签,是LSR自己计算的,没有规则可言,从前面的传输过程可以看出,在MPLS网络中,LSR每次收到数据包,都要将标签改成对下一跳有利的标签才转发出去,这个对下一跳有利的标签就是自己看到的远程标签,也称为出口标签,这个标签就是邻居告诉自己的,因为看到什么标签才能正确转发,邻居是知道的,所以告诉给其它邻居之后,才能保证最终路径的正确。 打标签 所有LSR,根据路由表,将数据包打上标签,发出去,打的这个标签不能乱打,是有意义的,因为下一跳路由器要根据这个标签做出自己的决策,收到的路由器将顶部标签(上一跳路由器加的标签)去除,再加入出站标签,然后再下一跳路由器重复之前的动作,所以每一台路由器都需要对路由条目的标签达成共识,要不然这台路由器为数据包打上标签,给下一跳路由器,却不是按设想的接口发出去的,就不能到达目标网络。因此,每一台LSR必须明确哪个出站标签来交换哪个入站标签,标签对于邻接LSR来说是本地有效,没有全局意义,这和帧中继的PVC是一个道理。所以,基于这些,需要有一种标签分发协议来为所有的LSR分发一个正确的标签,只有这样,LSR才能根据标签将数据包正确地发到目标网络。 标签分发方式 标签分发有两种方式: 1.在已存在的IP路由协议中分发标签。 2.使用一种独立的协议来分发标签。 1.在现有的路由协议中分发 距离矢量路由协议,比如EIGRP很好做,直接绑在前缀上,因为这样的路由协议可以随意修改路由条目的内容。 链路状态路由协议,比如OSPF和ISIS就比较难,因为是发链路状态,而链路状态必须毫无更改地发给邻居,更改链路状态数据包是违背原理。 所以也就没有IGP做标签分发的工作,但是BGP却可以同时发前缀和标签(注:BGP发标签是有条件限制的)。 2.标签分发协议 最终建议使用独立的分发协议,不影响路由协议,但需要在LSR上额外运行协议。 以下是可以分发标签的协议 标记分发协议(TDP) 标签分发协议(LDP) 资源预留协议(RSVP) TDP是思科专有的标记分发协议,已经被LDP所取代。 LDP是IETF开发,功能广泛,所以只涉及LDP,因为TDP已不用了。 RSVP只用在MPLS TE中。 标签分发协议LDP 对于IP路由表中每一条IGP前缀,每台LSR都会进行本地捆绑,也就是为路由条目加上一个标签,这个标签称为本地标签,到时收到一个数据包后,看到顶部标签如果是自己所拥有的本地标签,那么就根据这个标签从相应接口转发出去,所以邻居把数据包发给自己时,必须在数据包上写好自己对自己有利的标签,那么要怎样才能让邻居写上一个能让自己看了就正确转发的标签呢,这就得自己把这个标签告诉邻居,自己把本地标签发给邻居后,这个标签对于邻居来说就称为远程标签,每当邻居要发送数据包给自己的时候,就先把数据包的顶部标签改成远程标签,也就是改成之前发给邻居的标签,邻居改好标签后,把数据包发给我们,我们就能够做出正确转发了,那么邻居也会像我们一样,把自己的本地标签再发给它们的邻居,因为他要把数据正确发给我们,也是由它的邻居在数据包上写好标签告诉它的。所以在邻居和邻居之后,是要大家协商好每条路由该写上什么标签后发给邻居。LSR把自己生成的本地标签,和邻居发过来的远程标签,不管是用的着的还是用不着的,统统都保存在一张标签表里,这个表称为LIB表(标签信息库)。LDP就是用来发送标签的协议。 已经介绍过,MPLS的标签,就像帧中继的PVC号码一样,只是每台设备唯一的,但是MPLS的标签,在设备上保持唯一还分两种,基于设备唯一和基于接口唯一。 如果基于设备,就是一条路由在一台设备上只有一个唯一的标签。 如果基于接口,就是一条路由在一台设备上,是每个接口都有一个唯一的标签。也就是说标签只要能保证在每个接口上是唯一的即可,在整台设备上可以重复多次。 但LSR可能有多个远程标签,因为可能有多个邻居LSR。 路由协议EIGRP会将所有邻居发给自己的路由条目存放在拓朴表里,再从拓朴表里选中最优最好的放到路由表也供自己使用,当路由表中的条目失效后,再从拓朴表中拿出次优的使用。而MPLS标签交换的LSR也像EIGRP那样,会把所有邻居发来的标签都存放在LIB表里(就像EIGRP的拓朴表),然后从路由会条目的多个标签中选择一个最优的使用,这个选择方法可以通过IGP路由表,选到的下一跳是谁,那就用谁发来的标签,被选中的正在使用的标签,全部都是存放在LFIB(标签转发信息库)表里的,就像EIGRP的路由表。 注:IOS中,LDP不会为BGP的IPv4前缀捆绑标签。 标签的选择都是根据IGP最优路径。 标签也可以不是LDP分发,比如TE中,由RSVP分发,在MPLS VPN中,由BGP分发。 因为MPLS的标签是加在数据包的二层帧头之上,三层包头之下,三层包头,被认为是上层协议,也就是有效负载,中间的LSR并不知道上层协议类型,因为标签不会写,但它也不需要知道,自己只会根据标签来做出转发决定;但是出站LSR需要知道,所以会为FEC分配一个本地标签,以用作报文的入站标签,这样就可以了解有效负载了。 LSR在查看标签时,是要看基于接口还是设备,如果是基于接口,不能单看标签,还要看接口,如果是基于设备的那就只看标签。 注:在IOS中,所有的标签交换控制的ATM(LC-ATM)接口都采用基于接口的模式,其它通通基于设备,也就是说CCIE R&S的考生,只需要关心基于设备的标签即可。 标签分发模式 LSR在向邻居分发标签的时候,有三个需要注意的地方,这三个地方分为: 1.标签分发模式 2.标签保持模式 3.LSP控制模式 1.标签分发模式: 是用来定义标签该什么时候发给邻居,分为两种方式: (1)下游被动DOD模式 (2)下游主动UD模式 (1)在DOD,即被动模式中,是LSR请求下游(路由表的下一跳)为某条路由分发标签,也就是说一台LSR并不知道某些路由自己该写上什么标签后发给下一跳,所以这时就去问邻居要,要来的自己就作为该路由的远程标签存放。 (2)在UD,即主动模式中,LSR不需要为路由请邻居请求标签,标签是邻居会主动发过来的,不用请求,所以在UD模式中,LSR发现一条路由,就马上将自己的本地标签发送给邻居作为远程标签。 在此可以得出一个结论,在DOD中,LSR会向路由条目的下一跳请求标签,所以LIB只显示一个远程标签。在UD中,因为可能有多个邻居发送标签过来,所以一条路由可以看到多个标签。 注:IOS除了LC-ATM,全部使用UD模式,也就是说有多个标签从邻居发来。 2.标签保存模式 用来定义LSR在将标签保存时,该保存多久,分两种方式: (1)自由的标签保持模式(LLR) (2)保守的标签保持模式(CLR) (1)在LLR中,LSR将所有的标签存放在LIB中,然后使用的放到LFIB中,不使用的也保存在LIB中,当路由变化时,马上从LIB中找到新的。 (2)在CLR中,LSR将用到的标签放入LFIB之后,不会在LIB中保存任何标签。 注:IOS中,除了LC-ATM接口,其它所有都使用LLR,也就是能在LIB中看到标签。 3.LSP控制模式 用来定义LSR什么时候应该为一条路由创建标签,创建出的这个标签就是自己的本地标签,发给邻居之后,邻居就称其为远程标签。分两种创建方式: (1)独立于LSP的控制模式 (2)非独立于LSP的控制模式 (1)LSR可以独立于其它LSR创建本地标签,称为独立模式,路由器在路由表中发现一个路由,就马上为该路由创建一个标签。 (2)在非独立模式时,LSR只有意识到它是某FEC的出站LSR时,或者从下一跳收到某路由的标签时,才会为路由条目创建本地标签,然后发给邻居作为远程标签,邻居收到后,然后又会再创建了发给它的邻居。 由上可以看出,独立于LSP的模式在LSP中还没有让所有的LSR完成标签,有些LSR就开始标签转发,所有这些数据包有可能不能被正确转发,有可能被丢弃。而非独立的模式,只有从邻居收到标签了,开始自己的标签,所以自己使用标签转发后,下一跳邻居肯定是能接受的,不可能因为下一跳不认识标签而被丢弃 。 注:IOS使用独立的LSP控制模式,也就是说发现一条FEC,就马上创建标签,ATM除外。
在标签转发中,LSR查看标签前20bit,并在LFIB中查找相应的值。 在IP转发中,查看IP地址,在CEF表中做出转发。 路由器可以查看第二层头部的协议字段,就知道是标签报文,然后查找LFIB,则带标签出去,所以查CEF就等于是查IP,则不带标签出去。 路由器要为路由条目打上标签,就必须有功能支持改写数据包包头,CEF是唯一一种可以用于标签报文转发模式的,CEF是可以改写数据包包头的,所以启用MPLS时,必须在路由器上开CEF,否则无标签。 比如查看路由10.1.1.0在CEF中的操作,可以使用命令 show ip cef 10.1.1.0 查看这条路由的过程 MPLS负载均衡 在IPv4存在多条相同metric出口时,标签的出站也会对应多个接口,出站的标签可以是相同的,也可以不同的;如果下一跳是同台设备,肯定相同,是不同设备会不同,也就独立分配。 当LSR中某条路由有多个下一跳,如果是有标签的和无标签的,无标签的不走,是考虑到MPLS VPN中数据会丢包,因为在MPLS VPN网络中,P路由器是没有两边私有网络的IP路由的,所以无法路由,最终造成丢包。 MPLS未知标签 通常LSR只接收和发送带标签的并且能理解的数据包,因为某些原因,标签没找到的话,IOS是默认采用丢弃行为,如果找不到标签也传,也不能保证别人能传不丢弃,所以就自己开始丢弃。 MPLS保留标签 MPLS 标签范围中,并不是所有的标签都是可以随便用的,有些是保留的,范围是0-15,有特殊作用,0是显式空(null),3是隐式空,1是路由器报警标签,14是OAM报警,其它还没定义。下面是某些保留标签的重要用途: 隐式空3标签 在MPLS网络中,P路由器是完全按照标签交换的,而边缘路由器PE是同时连接了MPLS网络和IP网络,因此,一个数据包在MPLS网络中传输到PE路由器的时候,PE路由器的工作是:结束标签交换过程,从而转入IP网络,而转入IP网络就要执行IP地址的查找。那么从此可以看出,一个标签数据包到达PE路由器之后,PE路由器第一步开始根据数据包的标签去查找LFIB表,通过查找LFIB之后发现已经不再是标签交换了,第二步就马上转入查IP路由表,最终在IP路由表里查到了结果,从IP网络中发出去。很明显,PE路由器既然最后不可能使用标签交换,而要使用IP交换的,又何必去查了LFIB表才知道结果呢。所以就考虑到一个方法,能不能让PE的上一跳路由器不要为数据包打标签,直接改成IP数据包就行了,这样上一跳路由器没有写标签,那么PE在收到数据包之后,就能马上查IP路由表而做出转发。在这里,要让PE的上一跳路由器不要为数据打标签而直接改成IP数据包,这还得需要PE来告诉它才行。正常情况下,PE路由器是告诉上一跳正常的标签,上一跳将这个标签变成远程标签,但现在,PE路由器就不应该告诉上一跳正常的标签,它告诉的是隐式空(标签号为3)标签,所以收到标签为3的LSR,就不会在数据包发给下一跳时打上标签。这种终点使用隐式空标签来告诉上一跳不要打标签的行为叫倒数第二跳移除(PHP)行为,所以一台收到隐式空标签的LSR,相应出口就不再是一个远程标签,而应该在outgoing显示为pop。这种上一跳标签移除称为标签弹出。 注:在IOS中,PHP这种行为是默认的,但只会为直连路由和聚合路由通告隐式空3,但3不会明写。 显示空标签 显示空的功能是在隐式空的基础上的,IPv4标签号为0,IPv6为2。 因为标签中EXP用于QOS,前一跳移除后,这些信息也没了,可能希望保留,所以是上一跳将标签变为0,来告诉终点不用为0查找LFIB,只看EXP,所以只关心QOS效果,这样也省事。 路由器报警标签1,只是需要特别注意,并且软件转发。 未保留的都可以用,20个bit,是16-1048575,IOS默认是16-10 0000,IGP够了,但BGP可能不够,可以查看和修改标签范围。 MPLS TTL行为 在正常情况下,当数据包的TTL值减到0时,路由器会向源发ICMP类型11和代码0(时间超时)的数据包,来告诉源主机目标超时不可达。所以TTL无论对于IP网络还是MPLS网络都是非常重要的。 在数据包从IP网络进入MPLS网络时,IP刚进来,以前的TTL是多少,PE减1后,写到标签的TTL位,在出MPLS网络时,PE再看标签中的TTL是多少,肯定比IP原来的TTL值小,减1后写回去,如果TTL值比IP原来的TTL值还大,就不正常,就不写了。 标签到标签,添加和交换等操作,也是减1后再复制,中间P路由器只修改顶部标签中的TTL,顶部以下的标签是不动的。 如果遇见一个数据包TTL值为0,普通的MPLS网络就是沿原来的LSP回去,只有是IPv4和IPv6才会,其它的丢弃。 MPLS VPN中TTL没有后,是由终点PE或CE发回的,因为P没有源主机的路由,所以无法发送超时ICMP。 MPLS MTU OSI第三层网络层协议的包头是在第二层帧头之上的,也就是说在封装二层帧头的时候,是将数据内容和三层包头全部作为数据封装在里面的,对于二层来说,之前的数据最大是多少,就是由MTU来决定的,所以正常情况下MTU就是第三层数据和包头的最大尺寸,这时无需分段就能传输,如果比MTU大,就得分段后传输。但是MPLS的标签是在二层帧头之后的,所以二层帧头将标签的大小和三层包的内容累加到一起作为数据封装的,因为三层包的所有内容正好和MTU一样大,在此基础上加上MPLS标签的话,就肯定比额定的MTU要大,所以这时MPLS的标签数据是会被分段后传输的,如果不想被分段,就得更新MTU的大小。(一般MPLS数据包加最多两个标签,一个标签4字节,所以只要改成比正常MTU多8字节即可。)而改MTU还必须在MPLS网络中所有设备上进行更改,除非允许分段。 MPLS最大接收单元(MRU) 此内容无须配置 查看: sh mpls forwarding-table 1.1.1.1 detail MPLS默认超过MTU的数据包是和IP数据包一样要分段传输的,分段就是LSR移除标签,对IP数据分好相应大小后,再将原来的标签加到每个包,如果IP包头设置了不分段(DF),LSR就丢掉报文,然后返回一个需要分段的ICMP(不分段位设置为类型3,代码4),然后沿来的LSP发回去。 MTU路径发现(自动执行) 查看从源到目的的最小MTU,就是类似窗口的机制,数据包试着发出去,如果被丢了,就减小后再发,如果再丢就再减再发,直到能正常发到目的地为止。有时这个不太好用,因为ICMP不能返回,可能是防火墙挡住了。 标签分发 要让IGP全部都支持标签分发并且相互协同工作,不现实,所以新分发协议要独立于所有路由协议,那么就使用LDP,但是BGP可以广泛使用,范围大,最后BGP就自己发标签。LDP不为BGP的IPv4路由发送标签。 LDP运行 LDP运行时有四大功能: (1)运行LDP的LSR发现 (2)会话的建立和维护 (3)标签映射通告 (4)使用通知来进行管理
LDP是需要像OSPF那样建邻居的,使用hello包发现和维护邻居关系,LDP会在启用了的接口上发送hello来找邻居,发送hello用UDP 646,目的地为224.0.0.2,hello时间和保持时间分别是5秒15秒。这个hello包是不能跨网段传递的,而这个hello包被称为LDP Link Hello。 LDP在LSR之间除了建立邻居关系之外,还要建立LDP会话,建LDP会话就是用来交换标签的,使用的是TCP连接。而这个会话也只能和直连邻居建立,这样会话被称为LDP sessions。LDP会话的hello和超时分别是60秒和180秒。如果LDP邻居关系丢失,那么LDP会话也会断开。 配置MPLS
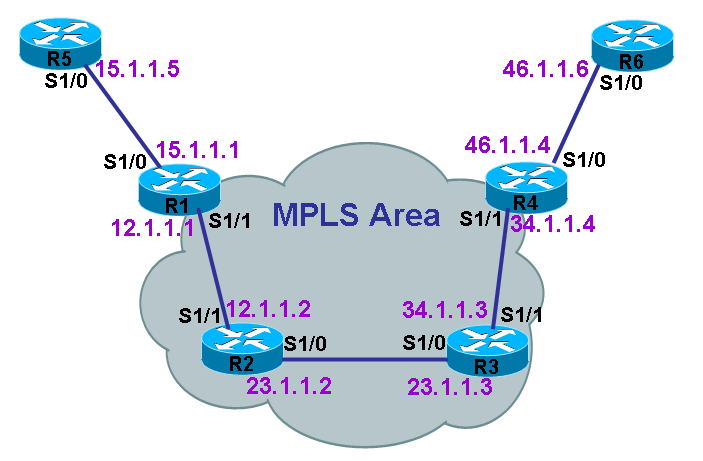
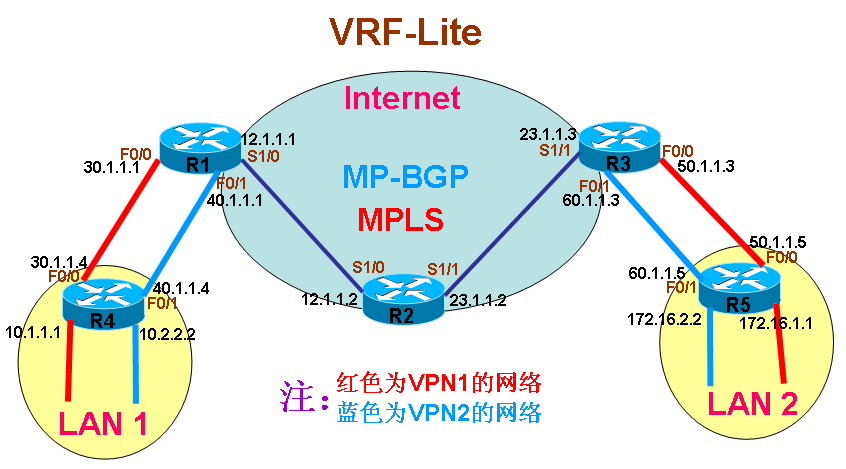
说明: 以上图为拓朴,配置MPLS,MPLS网络区域的范围是R1、R2、R3、R4,而R1和R4同时连接MPLS区域和IP网络,最终数据包在MPLS区域内传递时,我们将看到标签交换的效果。在开始配置之前,需要申明的是,每台路由器上都已配置looback0,地址分别为X.X.X.X/32,其中X表示设备号码,比如R2的loopback0地址为2.2.2.2/32,R5的loopback0地址为5.5.5.5/32;在所有设备中,已经启用OSPF协议,除了每台设备的接口loopback0没有放进OSPF进程以外,其它所有接口均在OSPF进程里通告。 1.查看和修改标签范围(可选配置) (1)看默认标签数量: R1#sh mpls label range Downstream Generic label region: Min/Max label: 16/100000 R1# 说明:默认标签范围是16到100000 (2)改标签范围: R1(config)#mpls label range 16 1010000 R1#sh mpls label range Downstream Generic label region: Min/Max label: 16/1010000 R1# 说明:已将标签范围改成:16到1010000 2.查看和修改MTU (可选配置) (1)查看路由器接口MTU: R1#show mpls int s1/1 detail (2)修改路由器接口MTU: R1(config)#int s1/1 R1 (config-if)#mpls mtu 1508 或 R1 (config)#int s1/1 R1 (config-if)#mtu 2000 注:某些IOS下的接口不能设置MTU,只能分段传输。 (3)修改交换机支持小巨型帧: sw(config)#system jumbomtu 2000 sw(config)#system mtu 2000 3.全局开启CEF (必须配置) 注:某些IOS版本已默认开启的,可跳过此步,请以自身IOS为准。 r1(config)#ip cef 4.配置LDP (必须配置) (1) 全局启用LDP: 说明:如果全局启用LDP,就将在此路由器的所有接口都开启LDP,但也可以选择只在某接口开启。 r1(config)#mpls label protocol ldp (2) 接口启用LDP: 说明:如果路由器并非全部接口都需要开启LDP,则只在相应接口开启。 r1(config)#int s1/1 r1(config-if)# mpls label protocol ldp (3)在接口下开启发hello包找邻居: r1(config)#int s1/1 r1(config-if)#mpls ip 说明:接口上配置mpls ip 就算打开了 IOS有时还在使用tag-switching来代替mpls ip,但功能是一样的,这两个命令相等。 注:请按上述配置LDP的方法,在MPLS区域内的所有路由器所有相关接口开启LDP并发出hello包,以方便LDP邻居的建立。 附:按以上拓朴,总结出需要的配置为: R1: r1(config)#int s1/1 r1(config-if)# mpls label protocol ldp r1(config-if)#mpls ip
R2: R2(config)#mpls label protocol ldp R2(config)#int s1/0 R2(config-if)#mpls ip R2(config-if)#exit R2(config)#int s1/1 R2(config-if)#mpls ip
R3: R3(config)#mpls label protocol ldp R3(config)#int s1/0 R3(config-if)#mpls ip R3(config-if)#exit R3(config)#int s1/1 R3(config-if)#mpls ip
R4: R4(config)#int s1/1 R4(config-if)#mpls label protocol ldp R4(config-if)#mpls ip 5.查看LDP简单信息 (1)可以查看哪些接口开启了mpls: r1#sh mpls interfaces Interface IP Tunnel Operational Serial1/1 Yes (ldp) No Yes r1# 说明:可以看出,R1相关接口S1/1已经运行在LDP下。(其它设备接口状态略过!) (2)查看看LDP详情,包括包含hello时间,会话时间: r1#sh mpls ldp parameters Protocol version: 1 Downstream label generic region: min label: 16; max label: 100000 Session hold time: 180 sec; keep alive interval: 60 sec Discovery hello: holdtime: 15 sec; interval: 5 sec Discovery targeted hello: holdtime: 90 sec; interval: 10 sec Downstream on Demand max hop count: 255 Downstream on Demand Path Vector Limit: 255 LDP for targeted sessions LDP initial/maximum backoff: 15/120 sec LDP loop detection: off r1# 说明:可以看到,默认hello和hold分别是5s和15s,会话时间hello和hold分别是60s和180s。 (3)修改时间机制(并不建议修改): 注:两边保持时间不一样,选用小的一端,改了多个,也是用小的而不是最新的。 改hello: r1(config)#mpls ldp discovery hello interval 3 r1(config)#exi
r1#sh mpls ldp parameters Protocol version: 1 Downstream label generic region: min label: 16; max label: 100000 Session hold time: 180 sec; keep alive interval: 60 sec Discovery hello: holdtime: 15 sec; interval: 3 sec Discovery targeted hello: holdtime: 90 sec; interval: 10 sec Downstream on Demand max hop count: 255 Downstream on Demand Path Vector Limit: 255 LDP for targeted sessions LDP initial/maximum backoff: 15/120 sec LDP loop detection: off 说明:可以看到hello时间被改成了3s
r1#sh mpls ldp discovery detail Local LDP Identifier: 12.1.1.1:0 Discovery Sources: Interfaces: Serial1/1 (ldp): xmit/recv Enabled: Interface config Hello interval: 3000 ms; Transport IP addr: 12.1.1.1 LDP Id: 2.2.2.2:0; no host route to transport addr Src IP addr: 12.1.1.2; Transport IP addr: 12.1.1.2 Hold time: 15 sec; Proposed local/peer: 15/15 sec Reachable via 12.1.1.0/24 r1# 说明:也可以看到hello时间被改成了3s
再改: r1(config)#mpls ldp discovery hello interval 8 r1#sh mpls ldp parameters Protocol version: 1 Downstream label generic region: min label: 16; max label: 100000 Session hold time: 180 sec; keep alive interval: 60 sec Discovery hello: holdtime: 15 sec; interval: 8 sec Discovery targeted hello: holdtime: 90 sec; interval: 10 sec Downstream on Demand max hop count: 255 Downstream on Demand Path Vector Limit: 255 LDP for targeted sessions LDP initial/maximum backoff: 15/120 sec LDP loop detection: off r1# 说明:可以看到hello时间被改成了8s
r1#sh mpls ldp discovery detail Local LDP Identifier: 12.1.1.1:0 Discovery Sources: Interfaces: Serial1/1 (ldp): xmit/recv Enabled: Interface config Hello interval: 5000 ms; Transport IP addr: 12.1.1.1 LDP Id: 2.2.2.2:0; no host route to transport addr Src IP addr: 12.1.1.2; Transport IP addr: 12.1.1.2 Hold time: 15 sec; Proposed local/peer: 15/15 sec Reachable via 12.1.1.0/24 r1# 说明:在这可以看到hello时间还是选默认5s,因为这个小。
改会话时间(不建议): r1(config)#mpls ldp holdtime 150 r1#sh adjacency detail *Mar 1 01:32:03.063: %SYS-5-CONFIG_I: Configured from console by console r1#sh mpls ldp parameters Protocol version: 1 Downstream label generic region: min label: 16; max label: 100000 Session hold time: 150 sec; keep alive interval: 50 sec Discovery hello: holdtime: 15 sec; interval: 8 sec Discovery targeted hello: holdtime: 90 sec; interval: 10 sec Downstream on Demand max hop count: 255 Downstream on Demand Path Vector Limit: 255 LDP for targeted sessions LDP initial/maximum backoff: 15/120 sec LDP loop detection: off r1# 说明可以看到hold时间被改成了150s。 6.查看LDP邻居相关信息 (1)在R1上查看LDP discovery情况: r1#sh mpls ldp discovery detail Local LDP Identifier: 1.1.1.1:0 Discovery Sources: Interfaces: Serial1/1 (ldp): xmit/recv Enabled: Interface config Hello interval: 5000 ms; Transport IP addr: 1.1.1.1 LDP Id: 2.2.2.2:0; no route to transport addr Src IP addr: 12.1.1.2; Transport IP addr: 2.2.2.2 Hold time: 15 sec; Proposed local/peer: 15/15 sec r1# 说明:Local LDP Identifier 是每台LSR都必须有的,这个ID用6个字节表示,前4个节字称为Rotuer-ID,先选loopback地址最大的,然后是物理接口,它的选举方法和OSPF Rotuer-ID相同,后面2个字节是表示标签空间的,也就是标签是基于设备还是基于接口,如果是基于设备,就是0,可以从上面看出,1.1.1.1:0中,1.1.1.1表示R1的Rotuer-ID,而0表示标签是基于设备的。再看后面还有个Transport IP ,而这个IP默认是选用Rotuer-ID的地址,这个地址在建邻居时非常重要,是会话的源地址,如果这个地址对方没有路由可达,那么就不可能建起邻居。所以一定要保证双方Transport IP 是路由相通的。从上面结果中还可以看出,R1已经收到了对方R2的hello,对方Transport IP是2.2.2.2,也就是对方的loopback0地址,而因为这个地址不在OSPF进程里,所以R1不能到达,也就不能建邻居,后面提示为“no route to transport addr”。 (2)在R2上查看LDP discovery情况: r2#sh mpls ldp discovery detail Local LDP Identifier: 2.2.2.2:0 Discovery Sources: Interfaces: Serial1/0 (ldp): xmit/recv Enabled: Interface config Hello interval: 5000 ms; Transport IP addr: 2.2.2.2 LDP Id: 3.3.3.3:0; no route to transport addr Src IP addr: 23.1.1.3; Transport IP addr: 3.3.3.3 Hold time: 15 sec; Proposed local/peer: 15/15 sec Serial1/1 (ldp): xmit/recv Enabled: Interface config Hello interval: 5000 ms; Transport IP addr: 2.2.2.2 LDP Id: 1.1.1.1:0; no route to transport addr Src IP addr: 12.1.1.1; Transport IP addr: 1.1.1.1 Hold time: 15 sec; Proposed local/peer: 15/15 sec r2# 说明:可以看出,R2的Rotuer-ID是2.2.2.2,这个地址也就是Transport IP,而R1的Transport IP是1.1.1.1,从上面也看出这两个地址是路由上互不相通的,所以不可能建立LDP邻居。
(3)解决邻居建立问题: 说明:要解决邻居建立问题,就要让双方的Transport IP能够相通,而Transport IP就是选用Rotuer-ID的IP地址,可以修改Rotuer-ID为可路由的接口,即可解决Transport IP互通。
改R1Router-Id为S1/1接口地址 r1(config)#mpls ldp router-id serial 1/1 force force说明立即生效 r1(config)#exi
查看结果: r1#sh mpls ldp discovery detail Local LDP Identifier: 12.1.1.1:0 Discovery Sources: Interfaces: Serial1/1 (ldp): xmit/recv Enabled: Interface config Hello interval: 5000 ms; Transport IP addr: 12.1.1.1 LDP Id: 2.2.2.2:0; no route to transport addr Src IP addr: 12.1.1.2; Transport IP addr: 2.2.2.2 Hold time: 15 sec; Proposed local/peer: 15/15 sec r1# 说明:可以看到Rotuer-ID已经改成接口S1/1的地址12.1.1.1,Transport IP也随即变成了12.1.1.1。
R1的Transport IP对R2来说已经可达了,可是R2的Transport IP还是自己的loopback口地址,R1不能到达,所以还是不能建邻居。Transport IP默认选用Rotuer-ID的地址,但我们可以明确指定Transport IP为某个接口的地址,这次我们直接改R2的Transport IP地址为S1/1的接口地址,Rotuer-ID不变: 先看没改之前: r2#sh mpls ldp discovery detail Local LDP Identifier: 2.2.2.2:0 Discovery Sources: Interfaces: Serial1/0 (ldp): xmit/recv Enabled: Interface config Hello interval: 5000 ms; Transport IP addr: 2.2.2.2 LDP Id: 3.3.3.3:0; no route to transport addr Src IP addr: 23.1.1.3; Transport IP addr: 3.3.3.3 Hold time: 15 sec; Proposed local/peer: 15/15 sec Serial1/1 (ldp): xmit/recv Enabled: Interface config Hello interval: 5000 ms; Transport IP addr: 2.2.2.2 LDP Id: 12.1.1.1:0; no host route to transport addr Src IP addr: 12.1.1.1; Transport IP addr: 12.1.1.1 Hold time: 15 sec; Proposed local/peer: 15/15 sec Reachable via 12.1.1.0/24 r2#conf t
现在修改: r2(config)#int s1/1 r2(config-if)#mpls ldp discovery transport-address interface r2(config-if)#exi
再看: r2#sh mpls ldp discovery detail Local LDP Identifier: 2.2.2.2:0 Discovery Sources: Interfaces: Serial1/0 (ldp): xmit/recv Enabled: Interface config Hello interval: 5000 ms; Transport IP addr: 2.2.2.2 LDP Id: 3.3.3.3:0; no route to transport addr Src IP addr: 23.1.1.3; Transport IP addr: 3.3.3.3 Hold time: 15 sec; Proposed local/peer: 15/15 sec Serial1/1 (ldp): xmit/recv Enabled: Interface config Hello interval: 5000 ms; Transport IP addr: 12.1.1.2 LDP Id: 12.1.1.1:0; no host route to transport addr Src IP addr: 12.1.1.1; Transport IP addr: 12.1.1.1 Hold time: 15 sec; Proposed local/peer: 15/15 sec Reachable via 12.1.1.0/24 r2# 说明:可以看到,s1/1上Transport IP已经不再是Router-ID的地址,已经被改成本接口地址了。但是接口S1/0还是使用原来Router-ID的地址。 但是邻居还是不会有,因为R2上直接改接口为Transport IP,是要重启进程才能生效的: r2#cle mpls ldp neighbor * r2# 再查看邻居: r2#sh mpls ldp neighbor Peer LDP Ident: 12.1.1.1:0; Local LDP Ident 2.2.2.2:0 TCP connection: 12.1.1.1.646 - 12.1.1.2.11155 State: Oper; Msgs sent/rcvd: 9/9; Downstream Up time: 00:00:43 LDP discovery sources: Serial1/1, Src IP addr: 12.1.1.1 Addresses bound to peer LDP Ident: 15.1.1.1 12.1.1.1 1.1.1.1 r2# 说明:可以看到,邻居已经有了,并且可以看出端口号是646。 (4)再来关心R2和R3的邻居: 说明:因为R2现在连R3的接口S1/0的Transport IP还是使用Router-ID的地址2.2.2.2,而R3也到不了2.2.2.2,所以R2和R3之间的LDP邻居关系是建不起来的,我们还是像R2和R1建邻居那样,把S1/0接口的Transport IP改成使用本接口的地址。 r2(config)#int s1/0 r2(config-if)#mpls ldp discovery transport-address interface r2(config-if)#exi 而R3的Transport IP还是使用自己的Router-ID地址3.3.3.3,这个地址R2也是无法到达的,在R3上也可以通过将该地址放进OSPF进程来使R2能够ping通,从而建立LDP邻居。 r3(config)#router ospf 2 r3(config-router)#network 3.3.3.3 0.0.0.0 area 0 r3(config-router)#exi 在R2上查看建LDP邻居的源地址: r2#sh mpls ldp discovery detail Local LDP Identifier: 2.2.2.2:0 Discovery Sources: Interfaces: Serial1/0 (ldp): xmit/recv Enabled: Interface config Hello interval: 5000 ms; Transport IP addr: 23.1.1.2 LDP Id: 3.3.3.3:0 Src IP addr: 23.1.1.3; Transport IP addr: 3.3.3.3 Hold time: 15 sec; Proposed local/peer: 15/15 sec Reachable via 3.3.3.3/32 Serial1/1 (ldp): xmit/recv Enabled: Interface config Hello interval: 5000 ms; Transport IP addr: 12.1.1.2 LDP Id: 12.1.1.1:0; no host route to transport addr Src IP addr: 12.1.1.1; Transport IP addr: 12.1.1.1 Hold time: 15 sec; Proposed local/peer: 15/15 sec Reachable via 12.1.1.0/24 r2# 说明:可以看到,R2连R3的接口S1/0的Transport IP 已经成功改成了23.1.1.2。 但是R2还是不会有R3的邻居,所以按以前方法重置LDP进程,再看就会有了: 来查看重置后的邻居状态: r2#sh mpls ldp neighbor Peer LDP Ident: 3.3.3.3:0; Local LDP Ident 2.2.2.2:0 TCP connection: 3.3.3.3.646 - 23.1.1.2.61206 State: Oper; Msgs sent/rcvd: 10/9; Downstream Up time: 00:00:09 LDP discovery sources: Serial1/0, Src IP addr: 23.1.1.3 Addresses bound to peer LDP Ident: 23.1.1.3 34.1.1.3 3.3.3.3 Peer LDP Ident: 12.1.1.1:0; Local LDP Ident 2.2.2.2:0 TCP connection: 12.1.1.1.646 - 12.1.1.2.44954 State: Oper; Msgs sent/rcvd: 10/10; Downstream Up time: 00:00:03 LDP discovery sources: Serial1/1, Src IP addr: 12.1.1.1 Addresses bound to peer LDP Ident: 15.1.1.1 12.1.1.1 1.1.1.1 r2# 说明:在R2上可以看见和R3的LDP邻居关系已经建立。 (5)R3跟R4的邻居关系: 说明:R3的Router-ID已经通告进OSPF进程,所以R4也能到达了,那么R4也选择将Loopback地址放loop进OSPF进程来完成和R3的LDP邻居关系建立。 说明:最终保证所有LDP 邻居建立(R1和R2的邻居,R2和R3的邻居,R3和R4的邻居全部都有)。 7.查看标签交换相关信息 说明:先以R4的loopback0地址4.4.4.4/32这条路由为例,来看别的路由器对这条路由的标签状况。 (1)在R4上查看LFIB,看路由4.4.4.4的情况: r4#sh mpls forwarding-table Local Outgoing Prefix Bytes tag Outgoing Next Hop tag tag or VC or Tunnel Id switched interface 16 Pop tag 23.1.1.0/24 0 Se1/1 34.1.1.3 17 16 12.1.1.0/24 0 Se1/1 34.1.1.3 18 18 15.1.1.0/24 0 Se1/1 34.1.1.3 19 Pop tag 3.3.3.3/32 0 Se1/1 34.1.1.3 r4# 说明:可以看出,R4上对自己直连接口的标签并没有出现在LFIB表中,因此该路由不需要进行标签交换,属正常。 (2) 查看R4上CEF对4.4.4.4的处理情况: 注:所有路由的处理,即使是打标签,都要由CEF来处理。 r4#sh ip cef 4.4.4.4 4.4.4.4/32, version 15, epoch 0, connected, receive tag information set local tag: implicit-null r4# 说明:可以看出,R4的CEF对4.4.4.4这条路由打的本地标签是implicit-null(隐式空标签,对于隐式空标签的解释,请参见MPLS正文内容),本地路由发给邻居之后,就成为了邻居的远程标签,所以邻居到达4.4.4.4的路由标签都应该是隐式空标签。 (3)查看R3的CEF对4.4.4.4的处理情况: r3#sh ip cef 4.4.4.4 4.4.4.4/32, version 19, epoch 0, cached adjacency 34.1.1.4 0 packets, 0 bytes tag information set local tag: 19 via 34.1.1.4, Serial1/1, 0 dependencies next hop 34.1.1.4, Serial1/1 valid cached adjacency tag rewrite with Se1/1, 34.1.1.4, tags imposed: {} r3# 说明:很明显,4.4.4.4在R4上的本地标签(implicit-null)发给R3之后,就成为了R3的远程标签,可以看到,因为R4发来时是隐式空,所以R3就不能为4.4.4.4打任何标签,所以最终结果的空的。而R3对于4.4.4.4这条路由是要生成自己的本地标签的,因为自己要对这条路由使用标签交换,可以看到R3自己给4.4.4.4打的本地标签是19,那么这个标签发给别的邻居之后,就该变成远程标签19。 (4)再查看R3的LFIB表: r3#sh mpls forwarding-table Local Outgoing Prefix Bytes tag Outgoing Next Hop tag tag or VC or Tunnel Id switched interface 16 Pop tag 12.1.1.0/24 0 Se1/0 23.1.1.2 17 Pop tag 46.1.1.0/24 0 Se1/1 34.1.1.4 18 18 15.1.1.0/24 0 Se1/0 23.1.1.2 19 Pop tag 4.4.4.4/32 0 Se1/1 34.1.1.4 r3# 说明:可以看到R3对于路由条目4.4.4.4的本地标签是19,这是要发给别人的,而出的标签是Pop tag,也就是要移除标签,也就是当R3收到邻居发来一个数据包,如果查看结果为顶部标签是19,那么自己就将该标签移除后,再从S1/0发出去。 (5) 查看R3的FIB表: 注:LSR对于路由条目所有的标签都是保存在FIB表里的,用到的才放进LFIB,所以在LFIB表里将可能看到路由的多个标签,但是只有一个标签是正被使用的。 r3#sh mpls ip binding 2.2.2.2/32 out label: imp-null lsr: 2.2.2.2:0 3.3.3.3/32 in label: imp-null out label: 19 lsr: 2.2.2.2:0 out label: 19 lsr: 4.4.4.4:0 4.4.4.4/32 in label: 19 out label: imp-null lsr: 4.4.4.4:0 inuse out label: 20 lsr: 2.2.2.2:0 12.1.1.0/24 in label: 16 out label: imp-null lsr: 2.2.2.2:0 inuse out label: 17 lsr: 4.4.4.4:0 15.1.1.0/24 in label: 18 out label: 18 lsr: 2.2.2.2:0 inuse out label: 18 lsr: 4.4.4.4:0 23.1.1.0/24 in label: imp-null out label: imp-null lsr: 2.2.2.2:0 out label: 16 lsr: 4.4.4.4:0 34.1.1.0/24 in label: imp-null out label: 16 lsr: 2.2.2.2:0 out label: imp-null lsr: 4.4.4.4:0 46.1.1.0/24 in label: 17 out label: 17 lsr: 2.2.2.2:0 out label: imp-null lsr: 4.4.4.4:0 inuse r3# 说明:从以上结果看出,路由条目4.4.4.4的in标签,即本地标签是19,而出的标签有两个,分别是20和imp-null ,而imp-null 后面有关键字inuse,也就表示imp-null是正在使用中的。 (6) 查看R2的LFIB: r2#sh mpls forwarding-table Local Outgoing Prefix Bytes tag Outgoing Next Hop tag tag or VC or Tunnel Id switched interface 16 Pop tag 34.1.1.0/24 0 Se1/0 23.1.1.3 17 17 46.1.1.0/24 0 Se1/0 23.1.1.3 18 Pop tag 15.1.1.0/24 0 Se1/1 12.1.1.1 19 Pop tag 3.3.3.3/32 0 Se1/0 23.1.1.3 20 19 4.4.4.4/32 0 Se1/0 23.1.1.3 r2# 说明:正因为R3收到标签为19的数据包,才会移除标签后从S1/1发给R4,所以R2肯定是应该将R3发来的本地标签19变成自己的远程标签19,以上结果也显示,R2对4.4.4.4打的出标签正是19,而本地标签是20,也就是说当R2收到一个顶部标签为20的数据包,就将标签换成19后从S1/0发出去,发出去正好就是发给了R3,而R3根据自己的处理最终发到R4。R2给4.4.4.4打的本地标签20,发给谁也就会变成谁的远程标签20。 (7)查看R2的CEF对4.4.4.4的处理情况: r2#sh ip cef 4.4.4.4 4.4.4.4/32, version 25, epoch 0, cached adjacency 23.1.1.3 0 packets, 0 bytes tag information set local tag: 20 fast tag rewrite with Se1/0, 23.1.1.3, tags imposed: {19} via 23.1.1.3, Serial1/0, 0 dependencies next hop 23.1.1.3, Serial1/0 valid cached adjacency tag rewrite with Se1/0, 23.1.1.3, tags imposed: {19} r2# 说明:可以看出,R2将4.4.4.4的本地标签改成20,将出的标签改成19(19正是R3上的本地标签)。所以和上面的理论全部对应。 (8)查看R1的LFIB表: r1#sh mpls forwarding-table Local Outgoing Prefix Bytes tag Outgoing Next Hop tag tag or VC or Tunnel Id switched interface 16 16 34.1.1.0/24 0 Se1/1 12.1.1.2 17 Pop tag 23.1.1.0/24 0 Se1/1 12.1.1.2 18 17 46.1.1.0/24 0 Se1/1 12.1.1.2 19 19 3.3.3.3/32 0 Se1/1 12.1.1.2 20 20 4.4.4.4/32 0 Se1/1 12.1.1.2 r1# 说明:从上面结果中看出,正因为R2对4.4.4.4打的本地标签是20,所以发给R1,就变成R1的远程标签,即出口标签是20了,而R1给4.4.4.4打的本地标签也是20,这是自己随意打上去的,从这个结果表明,当R1收到一个数据包标签为20的,那么就改成标签20从S1/1发出动。
(9)在R1上跟踪路由4.4.4.4的传输情况: r1#traceroute 4.4.4.4 Type escape sequence to abort. Tracing the route to 4.4.4.4
1 12.1.1.2 [MPLS: Label 20 Exp 0] 156 msec 220 msec 156 msec 2 23.1.1.3 [MPLS: Label 19 Exp 0] 168 msec 188 msec 196 msec 3 34.1.1.4 160 msec * 140 msec r1# 说明:因为对于条目4.4.4.4,R4给R3的标签为隐式空,即不打标签,R3给R2的标签为19,所以R2会打上标签19后发给R3,而R2给R1的标签是20,所以R1应该打上标签20后发给R2,那么在traceroute时,就看到了,给12.1.1.2(R2)打上的标签是20,然后发给23.1.1.3(R3)时打的标签是19,最后R3发给34.1.1.4(R4)时是没有打标签就发出去了。 (10)到IP网络R5上去traceroute 4.4.4.4: r5#traceroute 4.4.4.4 Type escape sequence to abort. Tracing the route to 4.4.4.4
1 15.1.1.1 136 msec 72 msec 84 msec 2 12.1.1.2 300 msec 368 msec 192 msec 3 23.1.1.3 252 msec 296 msec 148 msec 4 34.1.1.4 216 msec * 188 msec r5# 说明:从结果中发现,IP网络中发的数据在穿越MPLS区域时,标签的交换过程是看不见的,要想看到标签的交换过程,只有在MPLS网络中才能看见。 8.查看标签交换过程 说明:再以6.6.6.6这条路由条目为例,看一下它的标签如何。在边缘路由器R4上,会将IP网络的路由条目以隐式空标签发给邻居,但是默认只有自己直连的IP网络才会发隐式空标签,而6.6.6.6是在R6上的网段,不是R4的直连网段,所以对于6.6.6.6,R4不应该隐式空标签给邻居。 (1)查看R4上对6.6.6.6的标签情况: r4#sh mpls ip binding 3.3.3.3/32 in label: 19 out label: imp-null lsr: 3.3.3.3:0 inuse 4.4.4.4/32 in label: imp-null out label: 19 lsr: 3.3.3.3:0 6.6.6.6/32 in label: 20 out label: 20 lsr: 3.3.3.3:0 12.1.1.0/24 in label: 17 out label: 16 lsr: 3.3.3.3:0 inuse 15.1.1.0/24 in label: 18 out label: 18 lsr: 3.3.3.3:0 inuse 23.1.1.0/24 in label: 16 out label: imp-null lsr: 3.3.3.3:0 inuse 34.1.1.0/24 in label: imp-null out label: imp-null lsr: 3.3.3.3:0 46.1.1.0/24 in label: imp-null out label: 17 lsr: 3.3.3.3:0 r4# 说明:从结果中看出,因为4.4.4.4是R4的直连接口,所以本地标签(in label)是空的,而6.6.6.6不是自己直连网络,所以不应该打隐式空标签,可以看到它的本地标签(in label)是20。 (2)查看R4CEF里面的6.6.6.6: r4#sh ip cef 6.6.6.6 6.6.6.6/32, version 20, epoch 0, cached adjacency 46.1.1.6 0 packets, 0 bytes tag information set local tag: 20 via 46.1.1.6, Serial1/0, 0 dependencies next hop 46.1.1.6, Serial1/0 valid cached adjacency tag rewrite with Se1/0, 46.1.1.6, tags imposed: {} r4# 说明:也可以看出,6.6.6.6的处理不同于4.4.4.4,6.6.6.6的本地标签确实真实存在,是20.
(3)看到R3给6.6.6.6打的标签: r3#sh ip cef 6.6.6.6 6.6.6.6/32, version 20, epoch 0, cached adjacency 34.1.1.4 0 packets, 0 bytes tag information set local tag: 20 fast tag rewrite with Se1/1, 34.1.1.4, tags imposed: {20} via 34.1.1.4, Serial1/1, 0 dependencies next hop 34.1.1.4, Serial1/1 valid cached adjacency tag rewrite with Se1/1, 34.1.1.4, tags imposed: {20} r3# 说明:R3给6.6.6.6打本地标签是正常的,打了远程标签(出标签)是20,也在情理之中,因为不需要弹出标签(移除标签)。
(4)再看R3的LFIB表: r3#sh mpls forwarding-table Local Outgoing Prefix Bytes tag Outgoing Next Hop tag tag or VC or Tunnel Id switched interface 16 Pop tag 12.1.1.0/24 1672 Se1/0 23.1.1.2 17 Pop tag 46.1.1.0/24 0 Se1/1 34.1.1.4 18 18 15.1.1.0/24 540 Se1/0 23.1.1.2 19 Pop tag 4.4.4.4/32 1132 Se1/1 34.1.1.4 20 20 6.6.6.6/32 540 Se1/1 34.1.1.4 r3# 说明:R3对6.6.6.6出标签是20,说明处理也是正常的
(5)R2上看6.6.6.6的处理: r2#sh mpls forwarding-table Local Outgoing Prefix Bytes tag Outgoing Next Hop tag tag or VC or Tunnel Id switched interface 16 Pop tag 34.1.1.0/24 0 Se1/0 23.1.1.3 17 17 46.1.1.0/24 0 Se1/0 23.1.1.3 18 Pop tag 15.1.1.0/24 520 Se1/1 12.1.1.1 19 Pop tag 3.3.3.3/32 0 Se1/0 23.1.1.3 20 19 4.4.4.4/32 756 Se1/0 23.1.1.3 21 20 6.6.6.6/32 540 Se1/0 23.1.1.3 r2# 说明:R3的本地标签20,变成R2的出标签20,正常,而R2给6.6.6.6打的本地标签21,发给邻居将成为远程标签。 (6)再看R1对6.6.6.6的处理: r1#sh mpls forwarding-table Local Outgoing Prefix Bytes tag Outgoing Next Hop tag tag or VC or Tunnel Id switched interface 16 16 34.1.1.0/24 0 Se1/1 12.1.1.2 17 Pop tag 23.1.1.0/24 0 Se1/1 12.1.1.2 18 17 46.1.1.0/24 0 Se1/1 12.1.1.2 19 19 3.3.3.3/32 0 Se1/1 12.1.1.2 20 20 4.4.4.4/32 0 Se1/1 12.1.1.2 21 21 6.6.6.6/32 0 Se1/1 12.1.1.2 r1# 说明:R1将R2发来的标签21变成自己的出标签(远程标签)21,正常,自己的本地标签也正常。
(7)在R1上跟踪路由的标签交换过程: r1#traceroute 6.6.6.6 Type escape sequence to abort. Tracing the route to 6.6.6.6
1 12.1.1.2 [MPLS: Label 21 Exp 0] 356 msec 284 msec 204 msec 2 23.1.1.3 [MPLS: Label 20 Exp 0] 388 msec 196 msec 192 msec 3 34.1.1.4 [MPLS: Label 20 Exp 0] 152 msec 268 msec 260 msec 4 46.1.1.6 244 msec * 172 msec r1# 说明:因为R4对于路由条目6.6.6.6没有采用隐式空标签,而给R3发了标签20,而R3给R2也发了标签20,R2给R1发了标签21,所以结果中显示数据包发由R1发给R2(12.1.1.2)时打的标签正是21,R2发给R3时,打的标签是20,重要的是R3在发给R4时,并没有移除标签,而是打了标签20发出去的。
(8)在IP网络R5上看6.6.6.6的标签交换情况: r5#traceroute 6.6.6.6 Type escape sequence to abort. Tracing the route to 6.6.6.6
1 15.1.1.1 180 msec 92 msec 60 msec 2 12.1.1.2 308 msec 256 msec 264 msec 3 23.1.1.3 368 msec 200 msec 200 msec 4 34.1.1.4 232 msec 252 msec 144 msec 5 46.1.1.6 248 msec * 408 msec r5# 说明:IP网络的R5没有看到标签交换情况,所以正常。 9.查看数据包交换数量 说明:可以在LSR上查看某条路由经过标签交换的数据包数量: (1)在R3上查看4.4.4.4有多少个数据包经过了标签交换: r3#sh mpls forwarding-table 4.4.4.4 detail Local Outgoing Prefix Bytes tag Outgoing Next Hop tag tag or VC or Tunnel Id switched interface 19 Pop tag 4.4.4.4/32 1744 Se1/1 34.1.1.4 MAC/Encaps=4/4, MRU=1504, Tag Stack{} 4CA18847 No output feature configured Per-packet load-sharing r3 (2)在R3上查看6.6.6.6有多少个数据包经过了标签交换: r3#sh mpls forwarding-table 6.6.6.6 detail Local Outgoing Prefix Bytes tag Outgoing Next Hop tag tag or VC or Tunnel Id switched interface 20 20 6.6.6.6/32 2028 Se1/1 34.1.1.4 MAC/Encaps=4/8, MRU=1500, Tag Stack{20} 4CA18847 00014000 No output feature configured Per-packet load-sharing 10.路由条目的标签限制 说明:在某些时候,并不希望LSR对相应的条目打上标签,那么就可以在LSR限制相应路由条目的标签通告或接收。
(1) 限制标签接收: 说明:在R1上测试限制接收6.6.6.6的标签: r1(config)#access-list 6 permit 6.6.6.6 r1(config)#mpls ldp neighbor 12.1.1.2 labels accept 6 说明:命令意思为只从邻居12.1.1.2那里接收ACL 6允许的路由条目的标签,其它的不接收。 (2)查看配置标签限制后的LFIB: r1#sh mpls forwarding-table Local Outgoing Prefix Bytes tag Outgoing Next Hop tag tag or VC or Tunnel Id switched interface 16 Untagged 34.1.1.0/24 0 Se1/1 12.1.1.2 17 Untagged 23.1.1.0/24 0 Se1/1 12.1.1.2 18 Untagged 46.1.1.0/24 0 Se1/1 12.1.1.2 19 Untagged 3.3.3.3/32 0 Se1/1 12.1.1.2 20 Untagged 4.4.4.4/32 0 Se1/1 12.1.1.2 21 21 6.6.6.6/32 0 Se1/1 12.1.1.2 r1# 说明:可以看到,除了6.6.6.6打上了标签21以外,其它路由条目全部都没有标签,说明配置正确。
(3)限制标签发送: 说明:可以在LSR限制从邻居处接收标签,同样也可以限制将什么样的路由发送标签给邻居。 下面测试在R3上限制只发送6.6.6.6的标签给R2,其它统统不发标签: 先看R2上在没有做限制时的标签情况: r2#sh mpls forwarding-table Local Outgoing Prefix Bytes tag Outgoing Next Hop tag tag or VC or Tunnel Id switched interface 16 Pop tag 34.1.1.0/24 0 Se1/0 23.1.1.3 17 17 46.1.1.0/24 0 Se1/0 23.1.1.3 18 Pop tag 15.1.1.0/24 3340 Se1/1 12.1.1.1 19 Pop tag 3.3.3.3/32 0 Se1/0 23.1.1.3 20 19 4.4.4.4/32 972 Se1/0 23.1.1.3 21 20 6.6.6.6/32 1188 Se1/0 23.1.1.3 说明:可以看到6.6.6.6和其它路由都有标签。
(4)在R3上配置只发6.6.6.6的标签给R2: r3(config)#access-list 2 permit 2.2.2.2 此地址必须为对方的Router-ID r3(config)#access-list 6 permit 6.6.6.6 匹配路由条目 r3(config)# no mpls ldp advertise-labels 此命令必须配,用以禁止正常标签传送,否则所有限制无效 r3(config)#mpls ldp advertise-labels for 6 to 2 对相应邻居做相应限制 r3(config)#exi (5)再看R2上6.6.6.6的标签情况: r2#sh mpls forwarding-table Local Outgoing Prefix Bytes tag Outgoing Next Hop tag tag or VC or Tunnel Id switched interface 16 Untagged 34.1.1.0/24 0 Se1/0 23.1.1.3 17 Untagged 46.1.1.0/24 0 Se1/0 23.1.1.3 18 Untagged 15.1.1.0/24 3340 Se1/1 12.1.1.1 19 Untagged 3.3.3.3/32 0 Se1/0 23.1.1.3 20 Untagged 4.4.4.4/32 972 Se1/0 23.1.1.3 21 20 6.6.6.6/32 1188 Se1/0 23.1.1.3 说明:可以看到,除了6.6.6.6有标签,其它都没有标签,说明配置生效。
(6)在R3上也可以看配置的效果: r3#sh mpls ldp bindings advertisement-acls Advertisement spec: Prefix acl = 6; Peer acl = 2
tib entry: 2.2.2.2/32, rev 13 tib entry: 3.3.3.3/32, rev 4 tib entry: 4.4.4.4/32, rev 15 tib entry: 6.6.6.6/32, rev 18 Advert acl(s): Prefix acl 6; Peer acl 2 tib entry: 12.1.1.0/24, rev 8 tib entry: 15.1.1.0/24, rev 12 tib entry: 23.1.1.0/24, rev 6 tib entry: 34.1.1.0/24, rev 2 tib entry: 46.1.1.0/24, rev 10 r3# LDP邻居认证 说明:邻居之间可以配置相应密码,如果密码不同,则邻居无法建立。 (1)配置R2对R1使用密码cisco,如果R1无密码,则邻居失败: r2(config)#mpls ldp neighbor 12.1.1.1 password 0 cisco r2(config)# 说明:指定邻居时,后面应该为邻居的Router-ID,0表示在内存中显示时不加密。其它邻居失败的效果略过,请自行配置查看。 LDP会话保护 在讲LDP时说过,LDP在建邻居时,需要用到hello包,在直连接口上发送hello包出去,这个hello包是不能跨网段传递的,而这个hello包被称为LDP Link Hello,如果对方有邻居回应了这个包,那么就建立LDP会话,称为LDP sessions,LDP会话建立后就可以传递标签,这是直连邻居。但是邻居也可以远程建立,也就是说不直连,那么这样的hello称为LDP Targeted Hello,而远程建立的会话就叫targeted session。一般情况下,两台直连LSR建立会话之后,如果链路断掉了,那么会话也就断掉了,所以所有标签等到会话再次建立后再次重新计算。但是当两台LSR之间链路断掉之后,如果他们之间还有备用链路的话,完全可以事先在备用链路上建个远程会话targeted session,这样的话,即使两台LSR之间直连链路断了,也可以因为还有远程会话而不用清空所有标签,等到直连链路恢复后,再切换回来。这就是开启会话保护之后,通过建立远程会话来保护标签表的作用,但要做这样的保护,LSR之间必须得有备用链路,否则无效。 配置保护时,指定在多少时间内,会话不要断开,流量继续发送,也可以为软重置提供保护。配置时应该双方路由器都配置会话保护,或者一方配了,另一方至少要能回应Targeted Hello。 上面就是利用会话保护的功能来为邻居之间在备用链路上创建远程会话(targeted session),远程会话可以保护邻居断掉之间不会马上断开,因为存在备用链路。这样的远程会话可以通过会话保护的功能来创建,除此之外,还有一种创建方法,那就是手工创建远程会话,下面分别来介绍这两种方法的配置。 配置
说明:R1的loopback0为1.1.1.1/32,R2的loopback0为2.2.2.2/32,R3的loopback0为3.3.3.3/32,OSPF在所有设备上开启,并且所有loopback均放入OSPF进程。LDP只在R1和R2之间的S1/0开启。从图中可以发现,当R1和R2之间的直连链路断掉以后,LDP会话也会断开的,但是R1和R2明明还可以通过R3建立远程会话连接。 1.配置会话保护 (1)在R1上开启会话保护: R1(config)# mpls ldp session protection (2)在R2上开启会话保护: R2(config)# mpls ldp session protection
(3)也可以通过ACL指定邻居和时间,如: router(config)#access 1 per 1.1.1.1 router(config)#mpls ldp session protection for 1 duration 90s 2.查看会话保护效果 (1)先看一下保护之前的邻居状态: r1#sh mpls ld neighbor Peer LDP Ident: 2.2.2.2:0; Local LDP Ident 1.1.1.1:0 TCP connection: 2.2.2.2.23261 - 1.1.1.1.646 State: Oper; Msgs sent/rcvd: 9/9; Downstream Up time: 00:00:04 LDP discovery sources: Serial1/0, Src IP addr: 12.1.1.2 Addresses bound to peer LDP Ident: 23.1.1.2 12.1.1.2 2.2.2.2 说明:可以看出没有任何远程会话的信息。 (2)查看开了会话保护的邻居状态: r1#sh mpls ld neighbor Peer LDP Ident: 2.2.2.2:0; Local LDP Ident 1.1.1.1:0 TCP connection: 2.2.2.2.39052 - 1.1.1.1.646 State: Oper; Msgs sent/rcvd: 11/11; Downstream Up time: 00:02:27 LDP discovery sources: Serial1/0, Src IP addr: 12.1.1.2 Targeted Hello 1.1.1.1 -> 2.2.2.2, active, passive Addresses bound to peer LDP Ident: 23.1.1.2 12.1.1.2 2.2.2.2 r1# 说明:可以看出和R2之间存在远程会话信息。 (3) 再看discovery信息: r1#sh mpls ld discovery detail Local LDP Identifier: 1.1.1.1:0 Discovery Sources: Interfaces: Serial1/0 (ldp): xmit/recv Enabled: Interface config Hello interval: 5000 ms; Transport IP addr: 1.1.1.1 LDP Id: 2.2.2.2:0 Src IP addr: 12.1.1.2; Transport IP addr: 2.2.2.2 Hold time: 15 sec; Proposed local/peer: 15/15 sec Reachable via 2.2.2.2/32 Serial1/1 (ldp): xmit Enabled: Interface config Hello interval: 5000 ms; Transport IP addr: 1.1.1.1 Targeted Hellos: 1.1.1.1 -> 2.2.2.2 (ldp): active/passive, xmit/recv Hello interval: 10000 ms; Transport IP addr: 1.1.1.1 LDP Id: 2.2.2.2:0 Src IP addr: 2.2.2.2; Transport IP addr: 2.2.2.2 Hold time: 90 sec; Proposed local/peer: 90/90 sec Reachable via 2.2.2.2/32 r1# 说明:同样能看到远程会话信息。
(4) 断开R1和R2之间的直连链路测试: r1#sh mpls ld discovery detail Local LDP Identifier: 1.1.1.1:0 Discovery Sources: Interfaces: Serial1/1 (ldp): xmit Enabled: Interface config Hello interval: 5000 ms; Transport IP addr: 1.1.1.1 Targeted Hellos: 1.1.1.1 -> 2.2.2.2 (ldp): active/passive, xmit/recv Hello interval: 10000 ms; Transport IP addr: 1.1.1.1 LDP Id: 2.2.2.2:0 Src IP addr: 2.2.2.2; Transport IP addr: 2.2.2.2 Hold time: 90 sec; Proposed local/peer: 90/90 sec Reachable via 2.2.2.2/32 r1#
r1#sh mpls ld neighbor Peer LDP Ident: 2.2.2.2:0; Local LDP Ident 1.1.1.1:0 TCP connection: 2.2.2.2.39052 - 1.1.1.1.646 State: Oper; Msgs sent/rcvd: 15/13; Downstream Up time: 00:03:27 LDP discovery sources: Targeted Hello 1.1.1.1 -> 2.2.2.2, active, passive Addresses bound to peer LDP Ident: 23.1.1.2 12.1.1.2 2.2.2.2 r1# 说明:可以看见,R1和R2之间的直连链路断开后,LDP会话还在。 3.手工配置远程会话 说明:之前是通过会话保护的功能产生的远程会话,下面通过手工创建远程会话。 (1) R1上创建远程会话: 说明:需要指定对方Router-ID地址 r1(config)#mpls ldp neighbor 2.2.2.2 targeted ldp 不指定LDP,默认为TDP
(2)R2上创建远程会话: R2(config)#mpls ldp neighbor 1.1.1.1 targeted ldp (3)查看效果: 先看建立之前的状态: r1#sh mpls ld neighbor Peer LDP Ident: 2.2.2.2:0; Local LDP Ident 1.1.1.1:0 TCP connection: 2.2.2.2.23261 - 1.1.1.1.646 State: Oper; Msgs sent/rcvd: 9/9; Downstream Up time: 00:00:04 LDP discovery sources: Serial1/0, Src IP addr: 12.1.1.2 Addresses bound to peer LDP Ident: 23.1.1.2 12.1.1.2 2.2.2.2 r1# 说明:可以看出没有任何远程会话的信息。
再看建立之后的: r1#sh mpls ldp neighbor Peer LDP Ident: 2.2.2.2:0; Local LDP Ident 1.1.1.1:0 TCP connection: 2.2.2.2.23261 - 1.1.1.1.646 State: Oper; Msgs sent/rcvd: 10/10; Downstream Up time: 00:01:23 LDP discovery sources: Serial1/0, Src IP addr: 12.1.1.2 Targeted Hello 1.1.1.1 -> 2.2.2.2, active, passive Addresses bound to peer LDP Ident: 23.1.1.2 12.1.1.2 2.2.2.2 r1#
r1#sh mpls ld discovery detail Local LDP Identifier: 1.1.1.1:0 Discovery Sources: Interfaces: Serial1/0 (ldp): xmit/recv Enabled: Interface config Hello interval: 5000 ms; Transport IP addr: 1.1.1.1 LDP Id: 2.2.2.2:0 Src IP addr: 12.1.1.2; Transport IP addr: 2.2.2.2 Hold time: 15 sec; Proposed local/peer: 15/15 sec Reachable via 2.2.2.2/32 Serial1/1 (ldp): xmit Enabled: Interface config Hello interval: 5000 ms; Transport IP addr: 1.1.1.1 Targeted Hellos: 1.1.1.1 -> 2.2.2.2 (ldp): active/passive, xmit/recv Hello interval: 10000 ms; Transport IP addr: 1.1.1.1 LDP Id: 2.2.2.2:0 Src IP addr: 2.2.2.2; Transport IP addr: 2.2.2.2 Hold time: 90 sec; Proposed local/peer: 90/90 sec Reachable via 2.2.2.2/32 r1# 说明:可以看出和R2之间存在远程会话信息。
(4)断开R1和R2之间的直连链路测试: r1#sh mpls ld discovery detail Local LDP Identifier: 1.1.1.1:0 Discovery Sources: Interfaces: Serial1/1 (ldp): xmit Enabled: Interface config Hello interval: 5000 ms; Transport IP addr: 1.1.1.1 Targeted Hellos: 1.1.1.1 -> 2.2.2.2 (ldp): active/passive, xmit/recv Hello interval: 10000 ms; Transport IP addr: 1.1.1.1 LDP Id: 2.2.2.2:0 Src IP addr: 2.2.2.2; Transport IP addr: 2.2.2.2 Hold time: 90 sec; Proposed local/peer: 90/90 sec Reachable via 2.2.2.2/32 r1#
r1#sh mpls ldp neighbor Peer LDP Ident: 2.2.2.2:0; Local LDP Ident 1.1.1.1:0 TCP connection: 2.2.2.2.23261 - 1.1.1.1.646 State: Oper; Msgs sent/rcvd: 15/13; Downstream Up time: 00:02:50 LDP discovery sources: Targeted Hello 1.1.1.1 -> 2.2.2.2, active, passive Addresses bound to peer LDP Ident: 23.1.1.2 12.1.1.2 2.2.2.2 r1# 说明:可以看见,R1和R2之间的直连链路断开后,LDP会话还在。 IGP和LDP同步 概述 在某些情况下,当LDP邻居还没有建立或者邻居丢失而没有为路由发送标签时,如果这时IGP邻居已经建立并学到路由条目后,就会开始IP交换,那么后来当LDP正常以后,可能会出现丢包的情况,那么就利用IGP和LDP同步的特性,来限制LSR,只有当IGP和LDP都认为某条链路该转发,才转发流量。 IGP和LDP同步的特性只能在接口下配置过mpls ip时可以使用,并且目前只支持OSPF和LDP的同步。当配置好同步以后,相应的接口下,OSPF邻居在LDP邻居还没有建立之前,自己是不会建立邻居关系的,但是可以配置一个最大等待时候,称为holddown时候,默认是没有配的,如果OSPF在这个holddown时间过后,LDP邻居还没有建立起来,那么自己还是会建立邻居关系,但是,当OSPF在LDP没有建立邻居关系时,自己从邻居收到的路由条目将会被打上Metric 65536,这个值是很大的。
配置
说明: OSPF在R1和R2之间开启,还在R1和R3之间开启,而LDP只在R1和R2之间的接口开启。并且R1的loopback0为1.1.1.1/32,R2的loopback0为2.2.2.2/32,R3的loopback0为3.3.3.3/32,所有loopback均放入OSPF进程。 1.配置IGP和LDP的同步 说明:在R1上配置IGP和LDP的同步 (1)在OSPF进程下开启IGP和LDP的同步: 注:同步只在接口下配置了mpls ip才会生效。同步在进程下开启之后,所以接口生效,也可以基于相应接口关闭。 R1(config)#router os 2 R1(config-router)#mpls ldp sync 2.查看配置 r1#sh ip ospf mpls ldp interface Serial1/1 Process ID 2, Area 0 LDP is not configured through LDP autoconfig LDP-IGP Synchronization : Not required Holddown timer is disabled Interface is up Serial1/0 Process ID 2, Area 0 LDP is not configured through LDP autoconfig LDP-IGP Synchronization : Required Holddown timer is configured : 10000 msecs Holddown timer is not running Interface is up and sending maximum metric Loopback0 Process ID 2, Area 0 LDP is not configured through LDP autoconfig LDP-IGP Synchronization : Not required Holddown timer is disabled Interface is up r1# 说明:从结果中看出,只要接口S1/0同步才生效,因为只有此接口配了mpls ip,但是接口下并没有Holddown。 r1(config)#mpls ldp igp sync holddown 10000 3.配置Holddown 说明:配置了同步以后,OSPF在LDP没有建立邻居之前,自己是不会建立邻居关系的,但是如果超过了Holddown所限制的时间,即使LDP邻居关系还没有建立,OSPF还是会强行建立自己的邻居关系的。 4.查看同步的效果 说明:最终的效果为,在R2还没有配LDP之前,也就是R1的LDP邻居关系不能建立,在Holddown时间之前,OSPF邻居关系也没有,但是过了这个时间,LDP邻居还没有的话,OSPF还是会建立邻居的,但是R1将R2发过来的路由条目的Metric值设置成65536,然后发给邻居。 (1)在R1上查看R2发来的OSPF路由: 到R3上去看R2发给R1的路由,然后R1再发给自己后Metric是65536,正常情况下不是 r1#sh ip route Codes: C - connected, S - static, R - RIP, M - mobile, B - BGP D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2 E1 - OSPF external type 1, E2 - OSPF external type 2 i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2 ia - IS-IS inter area, * - candidate default, U - per-user static route o - ODR, P - periodic downloaded static route
Gateway of last resort is not set
1.0.0.0/32 is subnetted, 1 subnets C 1.1.1.1 is directly connected, Loopback0 2.0.0.0/32 is subnetted, 1 subnets O 2.2.2.2 [110/65536] via 12.1.1.2, 00:00:55, Serial1/0 3.0.0.0/32 is subnetted, 1 subnets O 3.3.3.3 [110/65] via 13.1.1.3, 00:00:55, Serial1/1 23.0.0.0/24 is subnetted, 1 subnets O 23.1.1.0 [110/74] via 13.1.1.3, 00:00:55, Serial1/1 12.0.0.0/24 is subnetted, 1 subnets C 12.1.1.0 is directly connected, Serial1/0 13.0.0.0/24 is subnetted, 1 subnets C 13.1.1.0 is directly connected, Serial1/1 r1# 说明:可以看到,R1上对于R2发来的路由条目2.2.2.2,Metric值是65546。 (2)在R3上查看路由: r3#sh ip route Codes: C - connected, S - static, R - RIP, M - mobile, B - BGP D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2 E1 - OSPF external type 1, E2 - OSPF external type 2 i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2 ia - IS-IS inter area, * - candidate default, U - per-user static route o - ODR, P - periodic downloaded static route
Gateway of last resort is not set
1.0.0.0/32 is subnetted, 1 subnets O 1.1.1.1 [110/65] via 13.1.1.1, 00:00:08, Serial1/1 2.0.0.0/32 is subnetted, 1 subnets O 2.2.2.2 [110/65600] via 13.1.1.1, 00:00:08, Serial1/1 3.0.0.0/32 is subnetted, 1 subnets C 3.3.3.3 is directly connected, Loopback0 23.0.0.0/24 is subnetted, 1 subnets C 23.1.1.0 is directly connected, FastEthernet0/0 12.0.0.0/24 is subnetted, 1 subnets O 12.1.1.0 [110/128] via 13.1.1.1, 00:00:08, Serial1/1 13.0.0.0/24 is subnetted, 1 subnets C 13.1.1.0 is directly connected, Serial1/1 r3# 说明:在R3上看到R1发来的路由2.2.2.2的Metric是设置了65536,再加上自己出口的64,结果为65600。 MPLS_VPN 概述 从前面可以看出,如果在英特网上大范围部署MPLS标签传输网络,这并没有给网络的的速度带来多少优势,而MPLS除了能够实现流量工程以外,还有一个很多人都认为很有优势的功能,那就是实现VPN,具体VPN的效果和VPN的作用,详细过程可以参见本站“IPSec VPN”主题部分。在理解MPLS_VPN之前,应对VPN的功能有正确的认识。正因为用户的网络都是私有网络地址,所以这些用户之间的私有网络传输,并不能在IP公网上面很好的传递,如果一旦用户的私有网络在公网上传递时,将会有无数个相同的私有网络,这将给IP网络带来麻烦。而又因为核心网部署MPLS网络之后,这样的网络可以不检查数据包的IP地址而进行传输,所以能让用户的私有网络在公网上传输的目的得以实现。不要忘了IPSec VPN同样可以做到这样的效果,而MPLS_VPN还有一个特点就是可以轻松实现多用户之间的全互联网络,但是我个人认为,这并不能称为MPLS_VPN的优势,因为用户要实现VPN传输,也许想要解决的,不仅仅是用私网地址通信这么单纯的目的,而数据的加密和安全性,也是应该被重点关心的,而这些,MPLS_VPN要做到是有难度的。不仅是这样,要完成两个远程用户网络之间的MPLS_VPN,必须得保护这两个远程网络之间所经过的所有核心网都要支持MPLS,而且核心网和用户网之间必须相互配合,不能出一点差错,否则也会给MPLS_VPN带来麻烦,也就是说,当任何一方对自己来说如果比较难以控制,那么要实施和排错MPLS_VPN将会存在相当的难度。而IPSec VPN,可以将所有问题统统解决在用户手里,也就是说实施和排错IPSec VPN时,用户将掌握所有控制权利,将问题解决在自己手中。所以上述两种VPN,用户可以根据自己的情况来作出选择,需要提醒的是,IPSec VPN存在着多种VPN架构,需要清楚地理解其每种架构的实现方法和作用。 下面来详细讲解MPLS_VPN的实现方式。
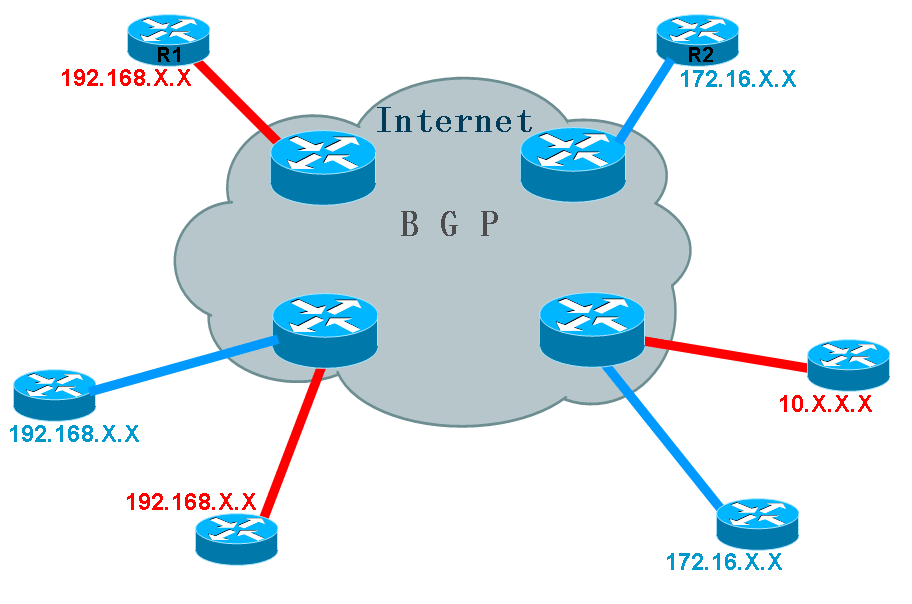
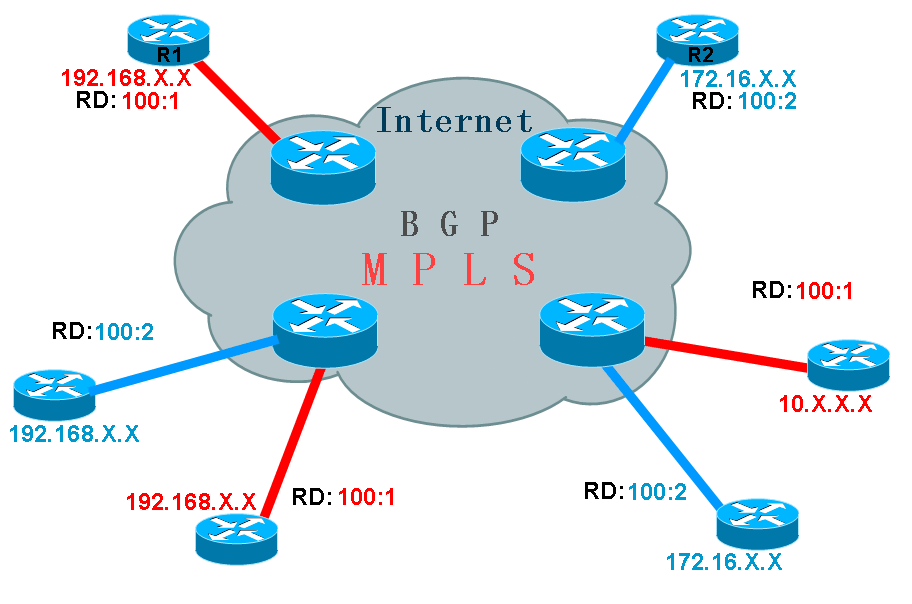
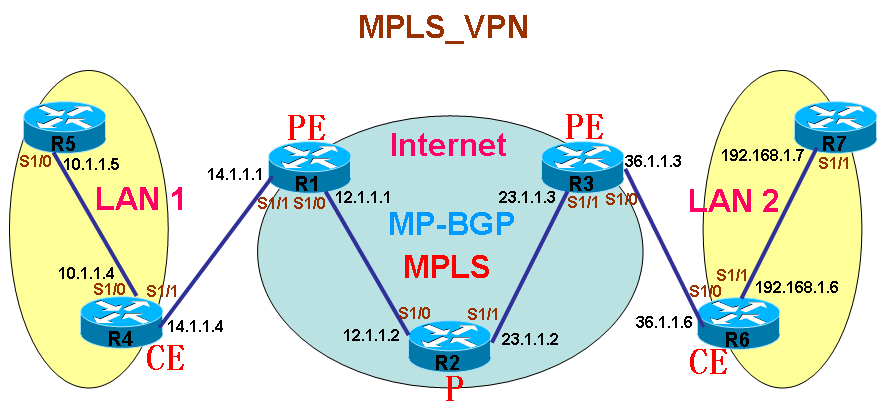
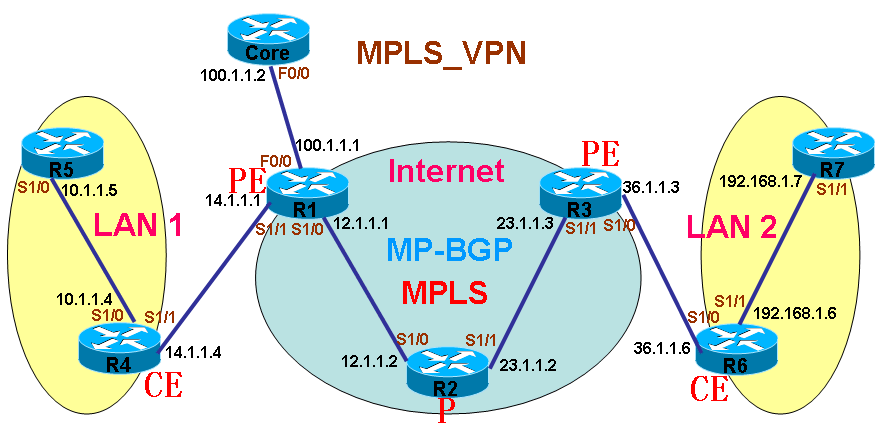
如上图所示,在Internet的边缘,连接着多个用户网络,这些用户网络使用的IP网段都是私有网段,如:192.168.0.0,172.16.0.0,10.0.0.0,而这些网段是无法在Internet上进行传递的,因为如果用户的私有网段被放入Internet时,将意味着有无数个用户网段会发生地址冲突,而最终导致Internet路由器无法区分这些网段谁是谁了。既然这样,用户之间要直接通过对方的私有地址进行访问,正常情况下是不可能的。那么要帮助用户将这些私有网段在Internet上进行传递,除非使用一些技术能够让这些私有网络在Internet上进行传递时,是唯一的,是互不干扰的。这样的技术其实已经存在,那就是在Internet中运行MPLS,因为在MPLS网络中,LSR是不看IP地址进行数据转发的,所以用户的私有网络在进入MPLS网络时,无论他们是私有的还是重叠都的,对于MPLS来说,这些都不是问题,只要他们的标签是正确的,就能被MPLS正确转发。 RD(路由区分符) 根据以上所说,在Internet核心内部运行MPLS网络之后,用户的私有网络可以在MPLS里面自由传递,但是用户要想到达另外的用户网络,终究也是要出MPLS网络的,当用户的网络在MPLS中到达Internet边缘路由器时,如果这些路由器还是无法区分用户的私有网络,那么通信的问题依旧存在。如果要消除这个大问题,那么就必须让Internet边缘路由器能够正确拥有用户的私有IP网络,并且要正确的区分他们,只有这样,用户之间的私有网络通信才能成为可能。(请看下图)
如上图所示,要让Internet边缘路由器拥有用户的私有网络,那么唯一的方法就是在边缘路由器与边缘路由器之间运行BGP,因为在MPLS中只要保证BGP之间的邻居地址可达就行,这个是可以轻易做到的,而当BGP在将用户的数据转入核心MPLS网络时,因为MPLS核心网络是只看标签而忽视用户私有网络的IP地址的,所以这不会存在任何问题, 虽然这样看来问题已经解决了,但是,还有一个最大的问题,那就是虽然Internet核心部分已经可以正确传递用户的私有网络了,Internet边缘路由器也成功的拥有了用户的私有网络地址,可是,用户的网络,毕竟是私有网段,即使BGP拥有了用户的私有网段,那么当存在着多个用户的私有网段时,他们的地址势必会重叠和冲突,就如上图所示,有多个用户的网段都是192.168.0.0或者都是172.16.0.0,这样的情况出现后,BGP也是无法区别用户的网络谁是谁了。要让BGP正确区分哪条私有网段是属于哪个用户,就还得给用户这些网段加上额外的标记才行,只有这样,才能让BGP正确区别各个用户网段并且允许他们重叠。 既然要给用户的私有网段再加上额外的标记让BGP能够正确区分他们,就得考虑这些标记是否能被正确支持。当考虑使用额外标记时,对于BGP来说,这已经不算问题,因为BGP可以视任何标记为外部属性,既然自己不能理解,也能很好的传递出去。 由于上述原因,便在用户的私有网段进入BGP时,就被加上了额外的标记以区分它们,这样的标记被称为路由区分符(RD)。所有的用户私有网络在被BGP传递时,都加入了RD,BGP要支持这些RD的传递,就是多协议的BGP(MP-BGP),所以MP-BGP在实现MPLS_VPN时,是必不可少的。 原来用户的网段地址长度都是32 bit,而RD长度是64 bit,当用户的地址被加上RD之后,就变成了96 bit,这样的地址被称为vpnv4。 RD的格式 RD分为两种格式: ASN:nn(常用)和IP-address:nn ASN代表BGP AS号码,nn代表数字,数字可以随便定义,只要合理即可,但这个数字,对于一台路由器上的不同用户,肯定是不同的。 比如一个用户的网段是10.1.1.0/24,RD是100:1,那么用户的vpnv4为100:1:10.1.1.0/24 VRF(虚拟路由表) 到此为止,还并不能让用户网络之间直接通过内网地址访问,也就是还不能实现VPN功能。 问题在于,当两个用户都连到同一台Internet边缘路由器时,比如他们的网段都是192.168.0.0/24,虽然运行了MP-BGP的边缘路由器能够区分它们是两条不同的路由条目,如下图所示:
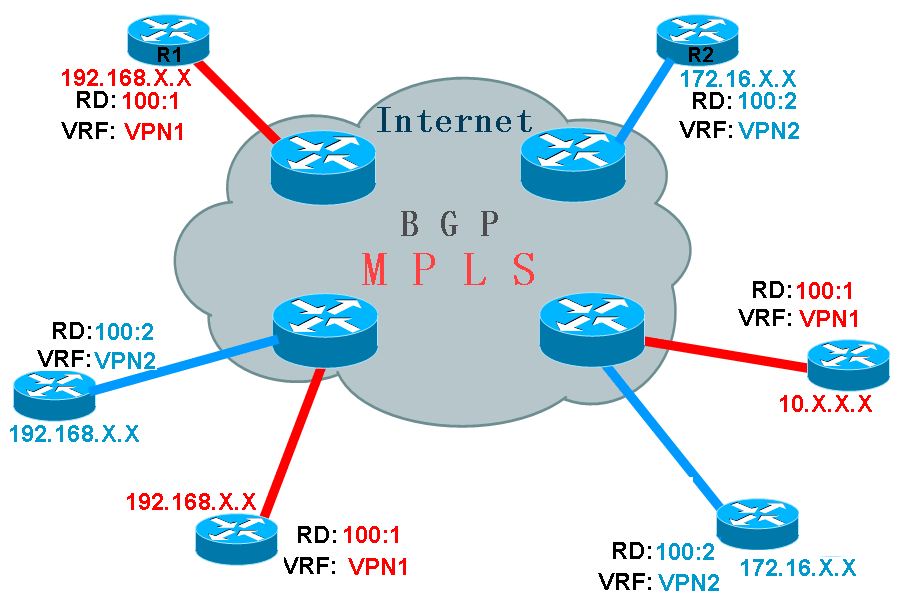
当左下角两个用户连到同一台边缘路由器时,因为两个用户的网段都是192.168.0.0,既然BGP能够知道它们是两条网段,可是当远程有一个用户,比如左上角的用户(左上角红色网络R1)要访问左下角红色网络时,它发出数据包的目的地址为192.168.0.0,边缘路由器又如何能够正确将该数据包发给红色网络的192.168.0.0,而不会错发给蓝色网络的192.168.0.0呢?这个问题值得思考。出现这样的问题,正因为边缘路由器中存在着两条192.168.0.0的网段,所以路由器无法区分数据包到底该发给谁,要解决这个问题,很明显,只要让路由器的路由表中只存在一条192.168.0.0的网段即可。那么又怎样才能让路由器中只存在一条不会重叠的私有网段呢,那就是在路由器上创建多个路由表,而这个路由表就只包含需要通信的用户网络,比如上图中只包含左上角红色网络和左下角红色网络,那么这样一来,当左上角红色网络R1要发数据包给左下角红色网络时,边缘路由器因为路由表中只存在一条192.168.0.0,所以就再也不会错把数据发给蓝色网络了。路由器上为需要通信的用户之间创建单独的路由表,这样的路由表被称为虚拟路由表(VRF),如果一台边缘路由器连接着多个不同用户,那么它将创建多个虚拟路由表,这个路由表和普通的路由表没有任何区别,只不过它只用来为VPN用户传递数据的,而与虚拟路由表相对的正常路由表被称为全局路由表。 RT(路由对象)
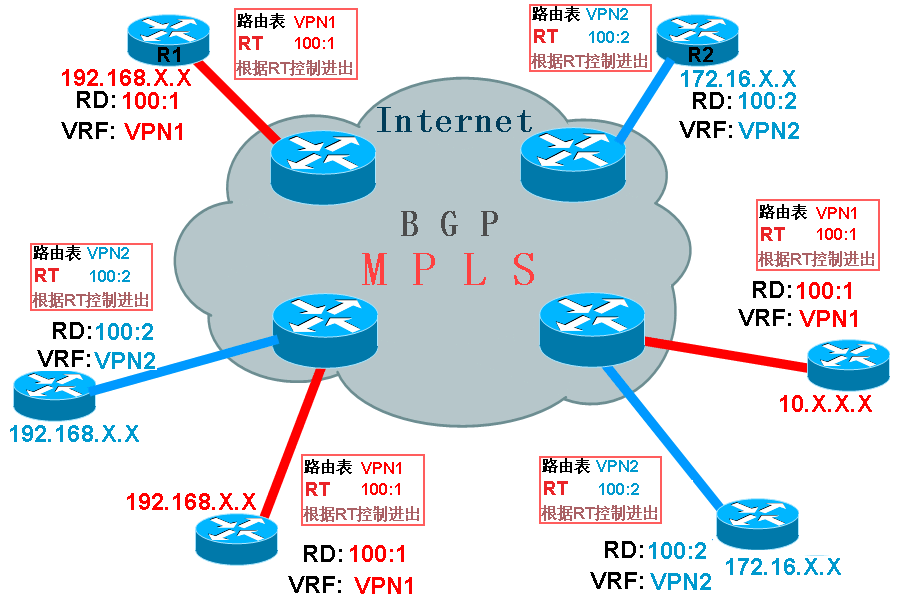
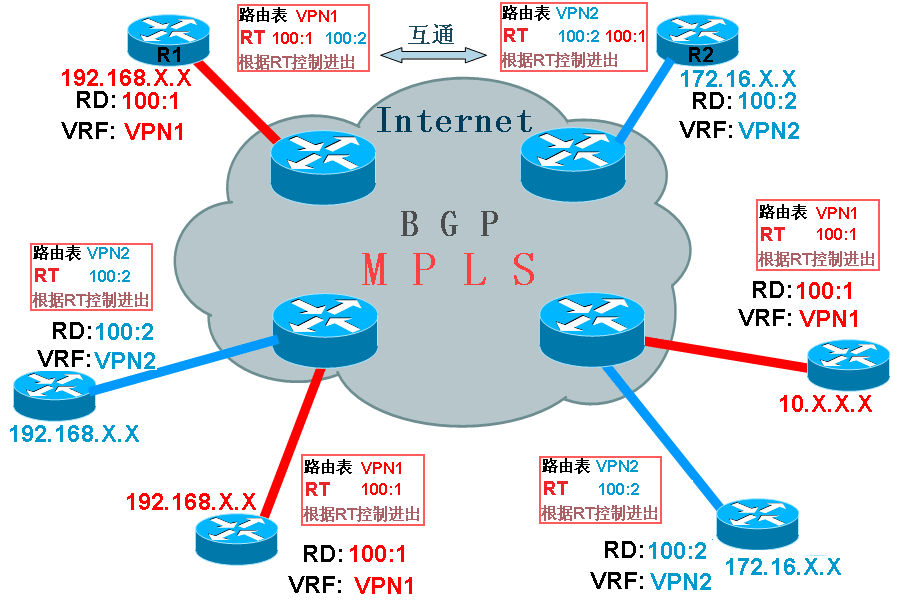
如上图所示,如果在刚才左下角的边缘路由器上为需要通信的红色网络创建出VRF之后,如VRF名字为VPN1,那么又如何保证只有需要通信的红色网络的网段会进入路由表,而其它不相关的网络(如蓝色网络)不会错误地被放进路由表呢?这些,都必须有所控制,否则用户之间的网络还是混乱的。 可以回想一下,之前我们说过,用户的网络在进入BGP之间,都是会被标记RD的,既然我们需要让红色的网络之间可以通信,让蓝色的网络不能进入VPN1,那么我们完全可以在给路由标记RD时,就将红色的网络标记为相同的RD,比如100:1,而将蓝色网络的RD标记为100:2,这样一来,边缘路由器就可以正确匹配它们了。因为我们已经为红色的网络创建了VRF为VPN1,而红色网络的RD都为100:1,蓝色网络的RD都为100:2,我们就可以完全控制只让RD为100:1的路由条目能够进入VPN1,这样就能达到我们所有的目的,并且不会混淆不同用户的网络。这样控制路由表只能进入什么样的路由或者只能出去什么样的路由,被称为RT(路由对象)。那么如果要让蓝色的网络之间可以相互通信,就可以为他们单独创建VRF,如VPN2,并且他们的RD是100:2,最终就可以控制RT只让RD为100:2的路由条目能够进入VPN2。通过这一切,就可以实现红色网络之间拥有单独的路由表而互通,让蓝色的网络也拥有自己单独的路由表而互通了。 上面所说的控制什么样的RD值能够进入什么样的VRF路由表,是RT(路由对象)来控制的,比如一个VRF为CCIE,用户的网段分别有RD为100:1的,也有100:2的和100:3的,我们只想让RD为100:3的路由条目能够进入CCIE的话,那么我们就可以设置CCIE的RT为100:3。这样做之后,只有RD为100:3的路由条目才能进入VRF CCIE,从而和其它RD为100:1和100:2的网络隔离开来。RT是BGP扩展团体属性,分为输入和输出两种,可以简单理解为什么样的RD值可以进入该VRF或者该VRF什么样RD值的路由将被导出。如果路由的RD值和RT所允许的值不匹配,将不能进入或者出去的,这样不同RD的用户也就不能通信,想要通信,就配置为相同的RD。但是一个VRF中,可以配置多个RT,也就是说一个VRF可以让多个不同RD值的路由进入或出去,最终结果为,如果要让两个不同RD的用户要通信,就分别为两个用户各自的VRF同时配置两个用户的RD,这样大家的VRF中都有互相的路由条目,也就可以互通了。如下图所示:
从上图中显示,红色网络中的R1和蓝色网络中的R2,默认情况下,他们是不能通信的,因为红色网络的VRF只允许RD为100:1的路由条目进入,而蓝色网络的VRF只允许RD为100:2的路由条目进入,但是配置为大家的VRF都同时允许RD为100:1和100:2进入,最后两个VRF中都有了对方的路由,也就实现了互通。 一般情况下,要通信的用户之间,RD都是配置为一样的,这样的通信称为内部通信,如果不同RD之间的网络也要通信,就可以分别在相互的VRF中配置RT允许双方的RD值都能进入和出去,也能够通信,这样的通信就称为外部通信。所以用户之间是否能通信,完全是由RT来控制的。RD是让BGP来区分用户路由条目的,VRF是让路由器来区分用户网络的。RT是用来控制VRF的路由进入和出去的。
ISP中存在P和PE,其中PE直接和用户相连,P则没有,但P和PE必须已经运行MPLS。 用户中存在CE和C,CE是直接和ISP相连的路由器,但都不需要运行MPLS。 CE和PE直接交互,所以必须运行路由协议,或者是写静态路由,CE只有一个对等PE,但也可多宿主,也就是和多PE相连, VPN,让P完全不用知道VPN,就不用负担VPN的路由信息了,则使用MPLS来实现,为用户的私有网络打上标签,然后P也不用运行BGP。但用户的路由必须在PE上出现,PE是必须了解用户私有网络的。 MP-BGP
如上图所示,用户局域网LAN1连接Internet,用户局域网LAN2也连接Internet,当LAN1要和LAN2直接通过内网地址进行相互访问时,只要之间实现MPLS_VPN即可,在实施MPLS_VPN时,Internet中之前是运行着MPLS的,我们已经知道,在MPLS中,中间的LSR称为P,而MPLS中连接着用户网络的边缘LSR称为PE,用户连接PE的路由器称为CE,而用户自己内部的路由器可以称为是C。 用户的网段到达PE时,因为要让BGP区分不同的用户网段,所以PE会为它加上RD,加上了RD的网段称为vpnv4,这时PE会将vpnv4的路由放入MP-BGP,然后MP-BGP再将vpnv4从MPLS网络中通告给对端的BGP邻居,但是要保证vpnv4到达对端BGP邻居之后,对方还能够认识这这些vpnv4的RD,那么BGP就必须为vpnv4打上相应的标签,对方BGP邻居看了这个标签,就能根据RD将其放入相应的VRF,从而将数据包根据这些VRF转发给相应的CE。正因为BGP要为vpnv4加入额外的标签,所以要使用MP-BGP。 在MPLS中,数据包可以被打上多个标签,而LSR在转发时,只看顶部的标签,也就是说在数据包的多个标签中,只有顶部这一个标签会被使用和修改,所以MP-BGP在给vpnv4加入标签时,只要加在顶部标签的下面,这样数据包在MPLS中传输时,就不会被修改了,所以对端BGP邻居能够正确识别数据包的相应RD,这也是为什么MPLS_VPN中数据包需要使用两个标签的理由。 MP-BGP规则 普通的BGP通过额外配置address-family之后,就可以实现MP-BGP的功能,普通的BGP只是能够传递普通IPv4的路由,所以这样也会有个默认address-family,称为ipv4,但是因为IP分为单播和多播,所以这种默认的address-family就是ipv4 unicast,如果要让BGP支持ipv4多播,那address-family就是ipv4 multicast。 如果要支持IPv6的单播和多播,那么address-family就分别为ipv6 unicast和ipv6 multicast。 在这里,以上的都不是我们要用到的address-family,因为我们要传递的即不是ipv4单播,也不是ipv4多播,更不是ipv6,我们要传递的是vpnv4,所以就要开启MP-BGP支持vpnv4,要支持vpnv4,也需要创建相应的vpnv4的address-family。并且需要创建相应的VRF,这样相应的vpn4就和相应的VRF相关联起来。所有多协议的BGP在运行之前,应该保证普通的BGP邻居是正常的。MP-BGP在为vpnv4通告标签时,并且所有信息要当作团体属性带出去,要手工指定。 注:IOS缺省为每个vpnv4分配一个唯一的MPLS 标签。
PE-CE路由协议 不同用户网络之间要通过MPLS_VPN进行通信,就需要PE上有用户网络的路由信息,PE再将这些路由在MP-BGP中通告给对端MP-BGP邻居。在这一切开始之前,PE就应该获得用户的内部路由信息,而让PE获得这些路由信息的方法,可以使用动态路由或静态路由,如果要使用动态路由,那么PE和CE之间就必须启用某些路由协议,否则如果PE上没有用户的私有网络,那么远程用户之间也就不可能通信了。在PE有了用户的路由协议之后,必须将这些路由信息重分布进MP-BGP,再由MP-BGP通告给对端邻居,从而到达远程用户,但是如果CE没有远程用户的私有网段信息,也是不能通信的,所以在PE上,MP-BGP的路由也同样要发给CE,也可以通过将MP-BGP的路由重分布进PE和CE间的路由协议,虽然普通BGP不允许将自己的路由重分布进IGP,但MP-BGP不受此限制。 还需要说明的是,PE和CE相连的某个接口,是属于某一个VRF的,所以从该接口进来的CE路由,都属于该VRF。
PE和CE之间支持的协议有 静态路由 RIPv2 OSPF EIGRP IS-IS 协议配置方法 在配置这些协议时,因为协议需要同时运行在PE和CE上,所以配置的步骤也分为PE和CE两步。 1.静态路由 (1)PE上直接对某个VRF写静态路由: r4(config)#ip route 0.0.0.0 0.0.0.0 14.1.1.4 (2)在PE上将静态路由重分布进MP-BGP: r1(config)#router bgp 100 r1(config-router)#address-family ipv4 vrf vpn1 r1(config-router-af)#redistribute static r1(config-router-af)#exi (3)CE上要有默认路由指向PE: r4(config)#ip route 0.0.0.0 0.0.0.0 14.1.1.1 2.RIPv2 注:RIP路由metric值超过15,路由无效,而外部路由重分布进RIP时,默认不指定metric的情况下,值为无穷大,所以默认将不显示在RIP中,所以请指明metric或配置default-metric (1)PE上配置RIP: r1(config)#router rip r1(config-router)#version 2 r1(config-router)#no auto-summary r1(config-router)#address-family ipv4 vrf vpn1 r1(config-router-af)#no auto-summary r1(config-router-af)#network 14.0.0.0 r1(config-router-af)#redistribute bgp 100 metric 1
(2)将RIP重分布进MP-BGP: r1(config)#router bgp 100 r1(config-router)#address-family ipv4 vrf vpn1 r1(config-router-af)#redistribute rip
(3)CE上正常配置RIP即可: r4(config)#router rip r4(config-router)#version 2 r4(config-router)#no auto-summary r4(config-router)#network 14.0.0.0 r4(config-router)#network 10.0.0.0 OSPF 说明:OSPF还具有Sham-lin(伪装链路的功能,此功能将不作任何讲述,如果CCIE R&S v4.0考试有该要求,本篇将立即加入详细讲解和配置过程!) (1)在PE上配置OSPF: r3(config)#router ospf 100 vrf vpn1 r3(config-router)#router-id 36.1.1.3 r3(config-router)#network 36.1.1.3 0.0.0.0 area 0 r3(config-router)#redistribute bgp 100 subnets (2)将OSPP重分布进MP-BGP:
r3(config)#router bgp 100 r3(config-router)#address-family ipv4 vrf vpn1 r3(config-router-af)#redistribute ospf 100 (3)CE正常配置OSPF: r6(config)#router ospf 100 r6(config-router)#router-id 6.6.6.6 r6(config-router)#network 36.1.1.6 0.0.0.0 area 0 r6(config-router)#network 192.168.1.6 0.0.0.0 area 0 r6(config-router)#exit r6(config)# EIGRP (1)在PE上配置EIGRP: r3(config)#router eigrp 1 r3(config-router)#no auto-summary r3(config-router)#address-family ipv4 vrf vpn2 r3(config-router-af)#no auto-summary r3(config-router-af)#network 83.1.1.3 0.0.0.0 r3(config-router-af)#autonomous-system 1 r3(config-router-af)#redistribute bgp 100 metric 10000 100 255 1 1500 (2)将EIGRP重分布进MP-BGP: r3(config)#router bgp 100 r3(config-router)#address-family ipv4 vrf vpn2 r3(config-router-af)#redistribute eigrp 1 (3)CE正常配置EIGRP: r8(config)#router eigrp 1 r8(config-router)#no auto-summary r8(config-router)#network 172.16.1.8 0.0.0.0 r8(config-router)#network 83.1.1.8 0.0.0.0
IS-IS暂且不作说明 EBGP IOS只支持CE和PE之间运行EBGP (1)PE上配置EBGP: r1(config)#router bg 100 r1(config-router)#address-family ipv4 vrf vpn1 r1(config-router-af)#neighbor 14.1.1.4 remote-as 200 r1(config-router-af)#neighbor 14.1.1.4 activate (2)和CE和EBGP默认会重分布进MP-BGP:
(3)CE上配置EBGP: r4(config)#router bgp 200 r4(config-router)#neighbor 14.1.1.1 remote r4(config-router)#neighbor 14.1.1.1 remote-as 100 r4(config-router)#network 10.1.1.0 mask 255.255.255.0 r4(config-router)#
如果所有客户网络AS都是一样的,CE会拒绝,因为看到与自己相同的AS,但服务提供商可以比较,如果是一样的,就修改成自己的发过去, 服务提供商配置为: r1(config)#router bgp 100 r1(config-router)#address-family ipv4 vrf vpn1 r1(config-router-af)#neighbor 14.1.1.4 as-override PE给CE再回来,hub-spoke,就配:nei allowas-in 1-10 配置MPLS_VPN 概述 以下面一张图为拓朴,详细介绍配置MPLS_VPN,其中R1、R2、R3上均已配置loopback0,地址分别为1.1.1.1/32,2.2.2.2/32,3.3.3.3/32,并且已经配置好OSPF,让MPLS区域内所有直连接口和loopback口互通。
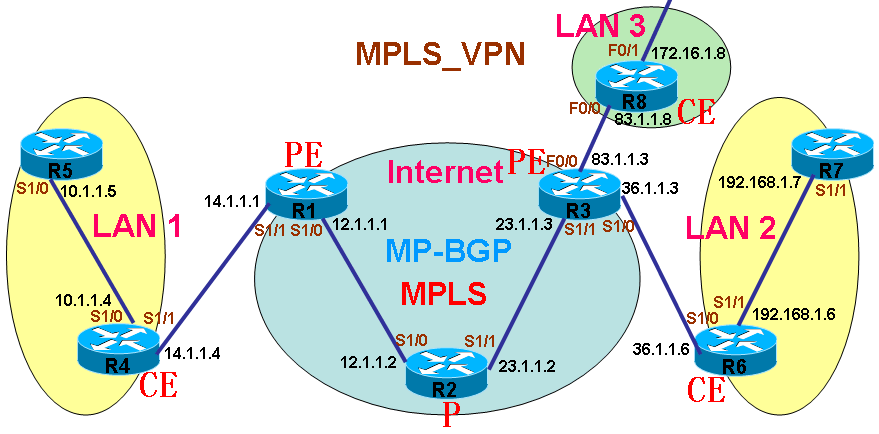
1.配置MPLS 说明:因为MP-BGP是配置MPLS_VPN的必须协议,在开始配置MPLS_VPN之前,应该先将MPLS区域的相关接口实现标签交换,如各自的直连口,loopback口均可看见已经通过标签进行交换。 (1) 配置MPLS区域略过,详细步骤请参见之前MPLS配置。 (2) 配置MPLS_VPN时,需要在边缘路由器R1和R3之间使用MP-BGP协议,我们使用路由器的loopback口作为源地址来建立邻居,首先测试双方loopback口已经实现标签交换。 r1#traceroute 3.3.3.3
Type escape sequence to abort. Tracing the route to 3.3.3.3
1 12.1.1.2 [MPLS: Label 17 Exp 0] 104 msec 120 msec 140 msec 2 23.1.1.3 72 msec * 112 msec r1# 说明:从结果可以看出,R1到R3的loopback0已经实现标签交换。
r3#traceroute 1.1.1.1
Type escape sequence to abort. Tracing the route to 1.1.1.1
1 23.1.1.2 [MPLS: Label 16 Exp 0] 100 msec 140 msec 196 msec 2 12.1.1.1 160 msec * 224 msec r3# 说明:从结果可以看出,R3到R1的loopback0已经实现标签交换。 2.配置普通BGP 说明:在R1和R3之间配置普通BGP,因为在配置MP-BGP之前,需要保证正常的BGP邻居是正常连通的 (1) 在R1上配置普通BGP: r1(config)#router bgp 100 r1(config-router)#neighbor 3.3.3.3 remote-as 100 r1(config-router)#neighbor 3.3.3.3 update-source loopback 0 (2)在R2上配置普通BGP: r3(config)#router bgp 100 r3(config-router)#neighbor 1.1.1.1 remote-as 100 r3(config-router)#neighbor 1.1.1.1 update-source loopback 0 (3)在R1上确认与R3的普通BGP邻居关系已建立: r1#sh ip bgp summary BGP router identifier 1.1.1.1, local AS number 100 BGP table version is 1, main routing table version 1
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd 3.3.3.3 4 100 3 3 1 0 0 00:00:51 0 r1# 说明:可以看到R1与R3已建立正常BGP邻居关系。 (4)在R3上确认与R1的普通BGP邻居关系已建立: r3#sh ip bgp summary BGP router identifier 3.3.3.3, local AS number 100 BGP table version is 1, main routing table version 1
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd 1.1.1.1 4 100 4 4 1 0 0 00:01:07 0 r3# 说明:可以看到R3与R1已建立正常BGP邻居关系。 3.在PE上创建VRF 说明:在PE上为用户创建相应的VRF,并且指定RD值,需要通信的两个用户网络之间,VRF和RD值保持一致。 (1)在R1上创建VRF,并指定RD值: r1(config)#ip vrf vpn1 r1(config-vrf)#rd 100:1 (2)在R3上创建VRF,并指定RD值: r3(config)#ip vrf vpn1 r3(config-vrf)#rd 100:1 4.在PE上将连CE的接口划入VRF 说明:在PE上将相应的CE接口划入相应的VRF,以后从该接口进入的用户数据包,则属于相应的VRF,该用户的数据只能根据该VRF路由表作出转发决策。 (1)在R1上将连CE R4的接口s1/1划入VRF: r1(config)#int s1/1 r1(config-if)#ip vrf forwarding vpn1 % Interface Serial1/1 IP address 14.1.1.1 removed due to enabling VRF vpn1 r1(config-if)# ip add 14.1.1.1 255.255.255.0 说明:当一个正常的接口被划入VRF之后,接口上的地址会消失,所以需要重新配置一次该接口的IP地址。 (2) 在R3上将连CE R6的接口s1/0划入VRF: r3(config)#int s1/0 r3(config-if)#ip vrf forwarding vpn1 % Interface Serial1/0 IP address 36.1.1.3 removed due to enabling VRF vpn1 r3(config-if)#ip add 36.1.1.3 255.255.255.0 5.在PE上查看VRF的路由表情况 说明:从用户发到PE的数据包,PE只能根据该用户的VRF路由表作出转发决策,也就是说,如果两个要通信的用户网络,如果各自的内网路由没有出现在PE的VRF路由表里,那么他们将不能通信, (1)在R1上查看VRF vpn1的路由表: r1#sh ip route vrf vpn1 Routing Table: vpn1 Codes: C - connected, S - static, R - RIP, M - mobile, B - BGP D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2 E1 - OSPF external type 1, E2 - OSPF external type 2 i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2 ia - IS-IS inter area, * - candidate default, U - per-user static route o - ODR, P - periodic downloaded static route
Gateway of last resort is not set
14.0.0.0/24 is subnetted, 1 subnets C 14.1.1.0 is directly connected, Serial1/1 r1# 说明:可以看见,PE在将连CE R4的接口s1/1划入VRF vpn1之后,该接口就进入VRF vpn1的路由表。并且要说明的是,该接口就不会再出现在全局路由表里。 (2) 查看PE R1的全局路由表,已经不会再有连CE接口s1/1的路由了: r1#sh ip route Codes: C - connected, S - static, R - RIP, M - mobile, B - BGP D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2 E1 - OSPF external type 1, E2 - OSPF external type 2 i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2 ia - IS-IS inter area, * - candidate default, U - per-user static route o - ODR, P - periodic downloaded static route
Gateway of last resort is not set
1.0.0.0/32 is subnetted, 1 subnets C 1.1.1.1 is directly connected, Loopback0 2.0.0.0/32 is subnetted, 1 subnets O 2.2.2.2 [110/65] via 12.1.1.2, 00:14:25, Serial1/0 3.0.0.0/32 is subnetted, 1 subnets O 3.3.3.3 [110/129] via 12.1.1.2, 00:14:25, Serial1/0 23.0.0.0/24 is subnetted, 1 subnets O 23.1.1.0 [110/128] via 12.1.1.2, 00:14:25, Serial1/0 12.0.0.0/24 is subnetted, 1 subnets C 12.1.1.0 is directly connected, Serial1/0 r1# 6.创建MP-BGP 说明:通过上面在PE上查看VRF路由表发现,VRF路由表中并没有双方用户的路由,所以,必须创建MP-BGP,来为双方用户网络传递路由信息。 (6 (1)在PE R1上创建MP-BGP: r1(config)#router bgp 100 r1(config-router)#address-family vpnv4 r1(config-router-af)#neighbor 3.3.3.3 activate r1(config-router-af)#neighbor 3.3.3.3 send-community both 说明:因为要传递vpnv4的路由,所以创建的address-family为vpnv4,并且将正常的BGP邻居在vpnv4里面激活,而且还需要将这些BGP的扩展属性手工强行发给对端,否则对方收到的路由信息不会携带扩展属性,也就无法正常区分用户的路由信息。
(2) 在PE R3上创建MP-BGP: r3(config)#router bgp 100 r3(config-router)#address-family vpnv4 r3(config-router-af)#neighbor 1.1.1.1 activate r3(config-router-af)#neighbor 1.1.1.1 send-community both
(3) 查看MP-BGP邻居: r1#sh ip bgp all summary For address family: IPv4 Unicast BGP router identifier 1.1.1.1, local AS number 100 BGP table version is 1, main routing table version 1
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd 3.3.3.3 4 100 23 23 1 0 0 00:03:18 0
For address family: VPNv4 Unicast BGP router identifier 1.1.1.1, local AS number 100 BGP table version is 1, main routing table version 1
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd 3.3.3.3 4 100 23 23 1 0 0 00:03:18 0 r1# 说明:可以看到,R1上已经和R3建立普通BGP邻居关系,同时也建立MP-BGP邻居关系。 7.查看MP-BGP的VRF路由 r1#sh ip bgp vpnv4 all
r1# 说明:在PE上只是已经创建了MP-BGP,并没有为BGP创建VRF,所以无法看到BGP中的VRF路由表信息,所以还需要手工创建VRF路由表。 8.为MP-BGP创建VRF 说明:MP-BGP在收到用户的路由信息后,必须将其放入相应的VRF路由表,但是这个VRF表是要手工创建的,并且和该用户相关联的VRF名字保持一致。 (1)在R1上为MP-BGP创建VRF vpn1: r1(config)#router bgp 100 r1(config-router)#address-family ipv4 vrf vpn1 (2)在R3上为MP-BGP创建VRF vpn1: r3(config)#router bgp 100 r3(config-router)#address-family ipv4 vrf vpn1 (3)查看已创建的VRF路由表的路由条目: r1#sh ip bgp vpnv4 all r1# r1#sh ip bgp vpnv4 vrf vpn1 r1# 说明:可以看到,BGP VRF路由表中并没有用户的路由信息。 9.配置RT控制VRF路由信息 说明:因为MP-BGP的VRF路由表能让什么样的路由进入,是靠RT来控制的,所以要想让用户的路由被MP-BGP传递,就必须为VRF配置相应的RT,只有RT允许的RD路由,才能进入和出去VRF表。 (1)在R1上为VRF配置相应的RT: r1(config)#ip vrf vpn1 r1(config-vrf)#route-target both 100:1 说明:VRF vpn1允许RD为100:1的路由进入和出去。 (2)在R3上为VRF配置相应的RT: r3(config)#ip vrf vpn1 r3(config-vrf)#route-target both 100:1 10.配置PE-CE的路由协议 说明:虽然MP-BGP的VRF已经允许相应的用户路由进入,但是在PE上,此时并不能获知用户的路由信息,所以MP-BGP的VRF路由表中,依然为空,要想让MP-BGP的VRF路由表能够导入相应的用户路由,那就必须和用户CE之前启用路由协议,以获得对方的路由信息,从而导入MP-BGP的VRF表。 (1)在PE R1上配置RIP: 说明:PE-CE路由协议RIP只支持版本2 r1(config)#router rip r1(config-router)#version 2 r1(config-router)#no auto-summary r1(config-router)#address-family ipv4 vrf vpn1 r1(config-router-af)#no auto-summary r1(config-router-af)#network 14.0.0.0 r1(config-router-af)#redistribute bgp 100 metric 1 注:发布路由都是在address-family中进行的,并且请关闭自动汇总功能,且将MP-BGP的路由重分布进RIP,否则对方CE将无法得知远程用户的路由信息。
(2)在CE R4上配置RIP: 说明:在CE上的路由协议和正常路由配置没任何区别,配置完协议后,将可以从PE上收到路由信息。 r4(config)#router rip r4(config-router)#version 2 r4(config-router)#no auto-summary r4(config-router)#network 14.0.0.0 r4(config-router)#network 10.0.0.0 (3)在PE R3上配置OSPF: 说明:同样也要将MP-BGP的路由重分布进OSPF,以便传递给CE端。 r3(config)#router ospf 100 vrf vpn1 r3(config-router)#router-id 36.1.1.3 r3(config-router)#network 36.1.1.3 0.0.0.0 area 0 r3(config-router)#redistribute bgp 100 subnets
(4) 在CE R6上配置OSPP: 说明:CE上的路由协议OSPF与正常OSPF配置无区别。 r6(config)#router ospf 100 r6(config-router)#router-id 6.6.6.6 r6(config-router)#network 36.1.1.6 0.0.0.0 area 0 r6(config-router)#network 192.168.1.6 0.0.0.0 area 0 r6(config-router)#exit r6(config)# 11.在PE上查看VRF路由 说明:已经在PE和CE配置路由协议,所以PE上应该已经获得用户的内部路由信息。 (1) 在R1上查看是否得到CE R4的内部路由信息10.1.1.0/24: r1#sh ip route vrf vpn1
Routing Table: vpn1 Codes: C - connected, S - static, R - RIP, M - mobile, B - BGP D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2 E1 - OSPF external type 1, E2 - OSPF external type 2 i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2 ia - IS-IS inter area, * - candidate default, U - per-user static route o - ODR, P - periodic downloaded static route
Gateway of last resort is not set
10.0.0.0/24 is subnetted, 1 subnets R 10.1.1.0 [120/1] via 14.1.1.4, 00:00:27, Serial1/1 14.0.0.0/24 is subnetted, 1 subnets C 14.1.1.0 is directly connected, Serial1/1 r1# 说明:PE R1已经成功通过路由协议RIP获得用户的内部路由信息。
(2) 查看MP-BGP的VRF路由表中是否已将用户的内部路由信息导入: r1#sh ip bgp vpnv4 all
r1# 说明:MP-BGP的VRF路由表还没有得到用户的内部路由信息,因为PE和CE之间运行的是IGP协议,所以要想让IGP学到的路由进入MP-BGP的VRF路由表,必须手工重分布。 12.将路由重分布进MP-BGP 说明:PE-CE之间在运行IGP时,无法自动导入MP-BGP,所以手工重分布。 (1)在R1上将RIP路由导入MP-BGP: r1(config)#router bgp 100 r1(config-router)#address-family ipv4 vrf vpn1 r1(config-router-af)#redistribute rip
(2)在R3上将OSPP路由导入MP-BGP: r3(config)#router bgp 100 r3(config-router)#address-family ipv4 vrf vpn1 r3(config-router-af)#redistribute ospf 100 13.查看MP-BGP路由 说明:MP-BGP已经和IGP之间实现重分布,查看双方路由是否获得。 (1)查看R1上MP-BGP的VRF路由表: r1#sh ip bgp vpnv4 all BGP table version is 9, local router ID is 1.1.1.1 Status codes: s suppressed, d damped, h history, * valid, > best, i - internal, r RIB-failure, S Stale Origin codes: i - IGP, e - EGP, ? - incomplete
Network Next Hop Metric LocPrf Weight Path Route Distinguisher: 100:1 (default for vrf vpn1) *> 10.1.1.0/24 14.1.1.4 1 32768 ? *> 14.1.1.0/24 0.0.0.0 0 32768 ? *>i36.1.1.0/24 3.3.3.3 0 100 0 ? *>i192.168.1.6/32 3.3.3.3 65 100 0 ? r1# 说明:已经拥有双方用户网络的内部路由信息。 (2)查看R3上MP-BGP的VRF路由表: r3#sh ip bgp vpnv4 all BGP table version is 9, local router ID is 3.3.3.3 Status codes: s suppressed, d damped, h history, * valid, > best, i - internal, r RIB-failure, S Stale Origin codes: i - IGP, e - EGP, ? - incomplete
Network Next Hop Metric LocPrf Weight Path Route Distinguisher: 100:1 (default for vrf vpn1) *>i10.1.1.0/24 1.1.1.1 1 100 0 ? *>i14.1.1.0/24 1.1.1.1 0 100 0 ? *> 36.1.1. 0/24 0.0.0.0 0 32768 ? *> 192.168.1.6/32 36.1.1.6 65 32768 ? r3# 14.查看VRF路由 说明:MP-BGP中已经拥有双方用户的网络信息,再看VRF中是否全部拥有。 (1)在R1上查看VRF表: r1#show ip route vrf vpn1
Routing Table: vpn1 Codes: C - connected, S - static, R - RIP, M - mobile, B - BGP D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2 E1 - OSPF external type 1, E2 - OSPF external type 2 i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2 ia - IS-IS inter area, * - candidate default, U - per-user static route o - ODR, P - periodic downloaded static route
Gateway of last resort is not set
36.0.0.0/24 is subnetted, 1 subnets B 36.1.1.0 [200/0] via 3.3.3.3, 00:02:50 10.0.0.0/24 is subnetted, 1 subnets R 10.1.1.0 [120/1] via 14.1.1.4, 00:00:04, Serial1/1 192.168.1.0/32 is subnetted, 1 subnets B 192.168.1.6 [200/65] via 3.3.3.3, 00:02:50 14.0.0.0/24 is subnetted, 1 subnets C 14.1.1.0 is directly connected, Serial1/1 r1# 说明:PE R1上的VRF已经拥有双方用户的网络信息,再看VRF中是否全部拥有。
(2)在R3上查看VRF表: r3#show ip route vrf vpn1
Routing Table: vpn1 Codes: C - connected, S - static, R - RIP, M - mobile, B - BGP D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2 E1 - OSPF external type 1, E2 - OSPF external type 2 i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2 ia - IS-IS inter area, * - candidate default, U - per-user static route o - ODR, P - periodic downloaded static route
Gateway of last resort is not set
36.0.0.0/24 is subnetted, 1 subnets C 36.1.1.0 is directly connected, Serial1/0 10.0.0.0/24 is subnetted, 1 subnets B 10.1.1.0 [200/1] via 1.1.1.1, 00:04:57 192.168.1.0/32 is subnetted, 1 subnets O 192.168.1.6 [110/65] via 36.1.1.6, 00:04:01, Serial1/0 14.0.0.0/24 is subnetted, 1 subnets B 14.1.1.0 [200/0] via 1.1.1.1, 00:04:57 r3# 说明:PE R1上的VRF已经拥有双方用户的网络信息,再看VRF中是否全部拥有。 15.查看CE路由 说明:因为PE上已经拥有双方用户的路由信息,并且PE和CE之间也运行路由协议,所以这些路由应该出现在CE的路由表中,从而双方用户可以实现通信。
(1)查看CE R4上的路由表: r4#sh ip route Codes: C - connected, S - static, R - RIP, M - mobile, B - BGP D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2 E1 - OSPF external type 1, E2 - OSPF external type 2 i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2 ia - IS-IS inter area, * - candidate default, U - per-user static route o - ODR, P - periodic downloaded static route
Gateway of last resort is not set
36.0.0.0/24 is subnetted, 1 subnets R 36.1.1.0 [120/1] via 14.1.1.1, 00:00:26, Serial1/1 10.0.0.0/24 is subnetted, 1 subnets C 10.1.1.0 is directly connected, Serial1/0 192.168.1.0/32 is subnetted, 1 subnets R 192.168.1.6 [120/1] via 14.1.1.1, 00:00:26, Serial1/1 14.0.0.0/24 is subnetted, 1 subnets C 14.1.1.0 is directly connected, Serial1/1 r4# r4# 说明:可以看到,CE R4上已经拥有所有用户的内部路由。 (2)查看CE R6上的路由表: r6#sh ip route Codes: C - connected, S - static, R - RIP, M - mobile, B - BGP D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2 E1 - OSPF external type 1, E2 - OSPF external type 2 i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2 ia - IS-IS inter area, * - candidate default, U - per-user static route o - ODR, P - periodic downloaded static route
Gateway of last resort is not set
36.0.0.0/24 is subnetted, 1 subnets C 36.1.1.0 is directly connected, Serial1/0 6.0.0.0/32 is subnetted, 1 subnets C 6.6.6.6 is directly connected, Loopback0 10.0.0.0/24 is subnetted, 1 subnets O E2 10.1.1.0 [110/1] via 36.1.1.3, 00:00:17, Serial1/0 C 192.168.1.0/24 is directly connected, Loopback192 14.0.0.0/24 is subnetted, 1 subnets O E2 14.1.1.0 [110/1] via 36.1.1.3, 00:00:17, Serial1/0 r6# 说明:可以看到,CE R6上已经拥有所有用户的内部路由。 16.测试用户之间通信 说明:因为用户CE之间已经拥有双方的内部路由信息,所以应该能够通信 (1)R5应该具有默认路由将所有数据从CE R4上发出去: r5#sh ip route Codes: C - connected, S - static, R - RIP, M - mobile, B - BGP D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2 E1 - OSPF external type 1, E2 - OSPF external type 2 i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2 ia - IS-IS inter area, * - candidate default, U - per-user static route o - ODR, P - periodic downloaded static route
Gateway of last resort is 10.1.1.4 to network 0.0.0.0
10.0.0.0/24 is subnetted, 1 subnets C 10.1.1.0 is directly connected, Serial1/0 S* 0.0.0.0/0 [1/0] via 10.1.1.4 r5# 说明:R5已经拥有指向CE R4的默认路由。
(2)LAN 1的R5上测试到 LAN 2的网段192.168.1.6的连通性: r5#ping 192.168.1.6
Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 192.168.1.6, timeout is 2 seconds: !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 188/242/288 ms r5# 说明:R5上已经成功穿越MPLS网络将数据包发送给远程用户网络,说明MPLS_VPN成功。
(3)跟踪路由: r5#traceroute 192.168.1.6
Type escape sequence to abort. Tracing the route to 192.168.1.6
1 10.1.1.4 64 msec 124 msec 48 msec 2 14.1.1.1 112 msec 92 msec 116 msec 3 12.1.1.2 260 msec 280 msec 236 msec 4 36.1.1.3 168 msec 196 msec 204 msec 5 36.1.1.6 268 msec * 248 msec r5# 说明:R5上已经成功穿越MPLS网络将数据包发送给远程用户网络,说明MPLS_VPN成功。 17.PE到CE的通信 说明:因为PE将连CE的接口放入VRF之后,该接口就从全局路由表中消失,所以和CE的通信,由VRF路由表决定。 (1) 查看PE的到CE的路由: r1#sh ip route Codes: C - connected, S - static, R - RIP, M - mobile, B - BGP D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2 E1 - OSPF external type 1, E2 - OSPF external type 2 i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2 ia - IS-IS inter area, * - candidate default, U - per-user static route o - ODR, P - periodic downloaded static route
Gateway of last resort is not set
1.0.0.0/32 is subnetted, 1 subnets C 1.1.1.1 is directly connected, Loopback0 2.0.0.0/32 is subnetted, 1 subnets O 2.2.2.2 [110/65] via 12.1.1.2, 00:51:02, Serial1/0 3.0.0.0/32 is subnetted, 1 subnets O 3.3.3.3 [110/129] via 12.1.1.2, 00:51:02, Serial1/0 23.0.0.0/24 is subnetted, 1 subnets O 23.1.1.0 [110/128] via 12.1.1.2, 00:51:02, Serial1/0 12.0.0.0/24 is subnetted, 1 subnets C 12.1.1.0 is directly connected, Serial1/0 r1# 说明:可以看到连CE的接口已经从全局路由表中消失。
(2)测试ping: r1#ping 14.1.1.4
Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 14.1.1.4, timeout is 2 seconds: ..... Success rate is 0 percent (0/5) r1# 说明:因为正常的ping是走的全局路由表,而全局路由表中没有到CE的接口,所以不通。 (3)使用VRF路由表: r1#ping vrf vpn1 14.1.1.4
Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 14.1.1.4, timeout is 2 seconds: !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 48/67/112 ms r1# 说明:通过指定到CE的数据走VRF路由表,所以最后通信成功。 点此查看配置实例所有设备的show running-config OSPF Sham-Link 在PE-CE路由协议为OSPF时,当OSPF和MP-BGP之间互相重分布时,请不要改变metric值,因为这里的metric值是受保护的,如果您改了,可能造成路由环路,请小心配置。 当PE和CE使用OSPF时,PE从CE学到路由后,都放在相应VRF中,然后传递给对端PE,再由PE转发到远程CE。 在OSPF中,当同时从intra-area(同一个区域)和inter-area(不同区域)学到相同路由时,intra-area中的路由总是被优先选中。
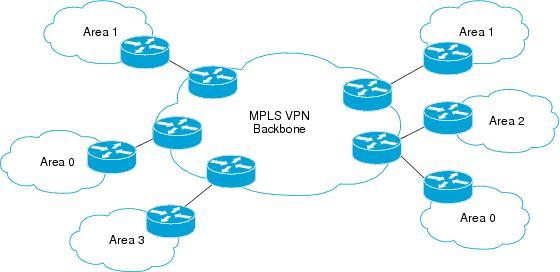
在上图中,有多个MPLS VPN场点同时连接到MPLS VPN骨干网络,PE-CE路由协议使用OSPF,OSPF区域分别有0、1、2、3,当MPLS VPN场点之间互相再连接链路后,这样的链路被称为后门链路(BackDoor),只要OSPF路由从这些后门链路上更新,那么势必会造成PE和CE路由器将MPLS VPN场点之间的流量优先选择从后门链路发送,而放弃从MPLS VPN骨干网络发送,原因为: *MPLS VPN骨干网络中为BGP,且为IBGP,管理距离为200,高于OSPF的值。 *PE和CE之间使用OSPF,从同区域学习到的路由优先于其它区域路由。
根据上图中得出,当CE路由器R3从与R4的后门链路学习到OSPF路由44.4.4.4之后,R3必定会优先选择从后门链路到达44.4.4.4,因为从后门链路学习到的路由为同区域的,都为区域1。不仅如此,PE路由器R1也同样会选择从后门链路到达44.4.4.4而放弃从MPLS VPN骨干网络中传输。如果CE之间的后门链路仅仅是作为备份使用,那么将其选作主用链路,是不理智的。 如果要让PE路由器和CE路由器都优先选择从MPLS VPN骨干网络到达远程VPN场点,解决方法为,在PE路由器之间也创建一个OSPF区域,这样一来,从后门链路到达远程场点是OSPF路径,从MPLS VPN骨干网络中到达远程网络同样也是OSPF路径,所以就能轻松地控制PE和CE路由器到达远程场点的路径。 在PE之间创建额外的OSPF区域的方法是创建OSPF Sham-Link,PE之间的Sham-Link相当于一条逻辑的链路,但是这条链路也属于某个OSPF区域,供PE路由器选路使用。只要PE路由器想要从MPLS VPN骨干网络到达远程网络,就等于从Sham-Link上到达远程网络。 在PE上创建OSPF Sham-Link需要注意的是: *OSPF Sham-Link也算是一条OSPF链路,这条链路可以指定为任何区域。 *当PE到CE再从后门链路到远程网络都属于同一个OSPF区域,即学习到的路由为intra-area路由时,必须将Sham-Link也指定为同一区域,因为如果Sham-Link属于另一区域,那么就表示从MPLS VPN骨干网络到达远程网络是inter-area路由,而inter-area路由是不可能优先于intra-area路由的,所以也就不可能让到达远程网络的路径从Sham-Link走。 *各个PE到CE,以及Sham-Link都可以属于不同的区域,即使这些链路属于不同的区域,也可以控制PE和CE的选路,选路规则就是intra-area路由和inter-area路由的区别。所以当出事各类区域时,请自己控制好选路。
配置Sham-Link时,需要满足以下条件: *在PE上单独创建/32位的地址,在PE之间使用这个地址来建立Sham-Link。 *这个/32位地址的接口必须放入相应的VRF。 *这个/32位地址必须在BGP里发布,而不能在OSPF里发布。
注:Sham-Link是有COST值的,PE穿越MPLS VPN骨干网络的OSPF COST值,就是Sham-Link的COST值,如果没有后门链路,Sham-Link就不需要创建了.。
配置OSPF Sham-Link
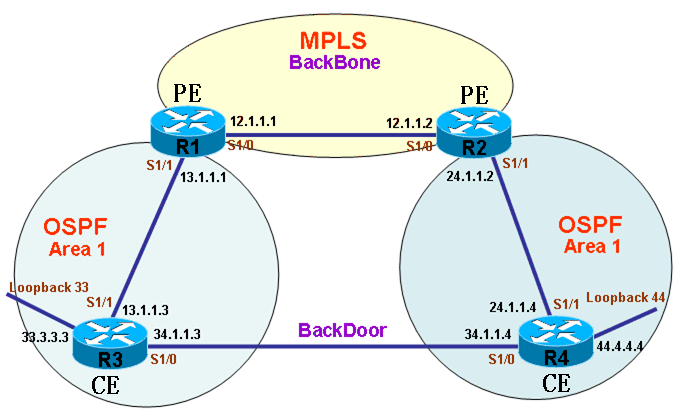
说明:在上图中,CE路由器R3和R4上分别有地址33.3.3.3和44.4.4.4,配置Sham-Link使PE路由器到达远程场点地址从MPLS VPN骨干网络中传输。 注:Sham-Link重要配置为第7步 1.配置R1与R2的路由协议为RIP (1)在R1上配置RIP r1(config)#router rip r1(config-router)#ver 2 r1(config-router)#no au r1(config-router)#network 1.0.0.0 (loopback0) r1(config-router)#network 12.0.0.0 (2)在R1上配置RIP r2(config)#router rip r2(config-router)#ver 2 r2(config-router)#no au r2(config-router)#network 2.0.0.0 (loopback0) r2(config-router)#network 12.0.0.0 2.在R1与R2上配置MPLS (1)在R1上配置MPLS
r1(config)#int s1/0 r1(config-if)#mpls ip
r1(config)#mpls ldp router-id loopback 0 force (2)在R2上配置MPLS r2(config)#int s1/0 r2(config-if)#mpls ip
r2(config)#mpls ld router-id loopback 0 force
3.配置MPLS VPN (1)在R1上配置MPLS VPN r1(config)#ip vrf vpn r1(config-vrf)#rd 100:1 r1(config-vrf)#route-target both 100:1
r1(config)#int s1/1 r1(config-if)#ip vrf forwarding vpn
(2)在R2上配置MPLS VPN r2(config)#ip vrf vpn r2(config-vrf)#rd 100:1 r2(config-vrf)#route-target both 100:1
r2(config)#int s1/1 r2(config-if)#ip vrf forwarding vpn
4.配置OSPF (1)在R1上配置OSPF r1(config)#router ospf 2 vrf vpn r1(config-router)#router-id 1.1.1.1 r1(config-router)#network 13.1.1.1 0.0.0.0 a 1 (2)在R2上配置OSPF r2(config)#router ospf 2 vrf vpn r2(config-router)#router-id 2.2.2.2 r2(config-router)#network 24.1.1.2 0.0.0.0 a 1 (3)在R3上配置OSPF r3(config)#router os 2 r3(config-router)#router-id 3.3.3.3 r3(config-router)#network 13.1.1.3 0.0.0.0 a 1 r3(config-router)#network 34.1.1.3 0.0.0.0 a 1 r3(config-router)#network 33.3.3.3 0.0.0.0 a 1 (4)在R4上配置OSPF r4(config)#router os 2 r4(config-router)#router-id 4.4.4.4 r4(config-router)#network 24.1.1.4 0.0.0.0 a 1 r4(config-router)#network 34.1.1.4 0.0.0.0 a 1 r4(config-router)#network 44.4.4.4 0.0.0.0 a 1
5.配置MP-BGP (1)在R1上配置MP-BGP r1(config)#router bgp 100 r1(config-router)#no au r1(config-router)#no sy r1(config-router)#bg router-id 1.1.1.1 r1(config-router)#neighbor 2.2.2.2 remote-as 100 r1(config-router)#neighbor 2.2.2.2 up loopback 0 r1(config-router)#address-family vpnv4 r1(config-router-af)#neighbor 2.2.2.2 activate r1(config-router-af)#neighbor 2.2.2.2 send-community both r1(config-router-af)#exit r1(config-router)#address-family ipv4 vrf vpn r1(config-router-af)#redistribute ospf 2
r1(config)#router os 2 vrf vpn r1(config-router)#re bgp 100 subnets
(2)在R2上配置MP-BGP r2(config)#router bgp 100 r2(config-router)#no au r2(config-router)#no sy r2(config-router)#bg router-id 2.2.2.2 r2(config-router)#nei 1.1.1.1 remote 100 r2(config-router)#neighbor 1.1.1.1 up loopback 0 r2(config-router)#address-family vpnv4 r2(config-router-af)#neighbor 1.1.1.1 activate r2(config-router-af)#neighbor 1.1.1.1 send-community both r2(config-router-af)#exit r2(config-router)#address-family ipv4 vrf vpn r2(config-router-af)#re ospf 2
r2(config)#router ospf 2 vrf vpn r2(config-router)#re bgp 100 subnets
6.查看路由 (1)查看PE路由器R1的路由 r1#sh ip bgp vpnv4 all BGP table version is 11, local router ID is 1.1.1.1 Status codes: s suppressed, d damped, h history, * valid, > best, i - internal, r RIB-failure, S Stale Origin codes: i - IGP, e - EGP, ? - incomplete
Network Next Hop Metric LocPrf Weight Path Route Distinguisher: 100:1 (default for vrf vpn) * i13.1.1.0/24 2.2.2.2 192 100 0 ? *> 0.0.0.0 0 32768 ? * i24.1.1.0/24 2.2.2.2 0 100 0 ? *> 13.1.1.3 192 32768 ? * i33.3.3.3/32 2.2.2.2 129 100 0 ? *> 13.1.1.3 65 32768 ? * i34.1.1.0/24 2.2.2.2 128 100 0 ? *> 13.1.1.3 128 32768 ? * i44.4.4.4/32 2.2.2.2 65 100 0 ? *> 13.1.1.3 129 32768 ? r1# 说明:PE路由器R1到达33.3.3.3和44.4.4.4都从CE路由器R3走。 (2)查看PE路由器R1的路由 r1#sh ip route vrf vpn
Routing Table: vpn Codes: C - connected, S - static, R - RIP, M - mobile, B - BGP D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2 E1 - OSPF external type 1, E2 - OSPF external type 2 i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2 ia - IS-IS inter area, * - candidate default, U - per-user static route o - ODR, P - periodic downloaded static route
Gateway of last resort is not set
34.0.0.0/24 is subnetted, 1 subnets O 34.1.1.0 [110/128] via 13.1.1.3, 00:01:38, Serial1/1 33.0.0.0/32 is subnetted, 1 subnets O 33.3.3.3 [110/65] via 13.1.1.3, 00:01:39, Serial1/1 24.0.0.0/24 is subnetted, 1 subnets O 24.1.1.0 [110/192] via 13.1.1.3, 00:01:39, Serial1/1 13.0.0.0/24 is subnetted, 1 subnets C 13.1.1.0 is directly connected, Serial1/1 44.0.0.0/32 is subnetted, 1 subnets O 44.4.4.4 [110/129] via 13.1.1.3, 00:01:39, Serial1/1 r1#
说明:PE路由器R1到达33.3.3.3和44.4.4.4都从CE路由器R3走。 7.在PE路由器之间创建Sham-Link (1)在PE路由器上创建/32位loopback地址 R1: r1(config)#int loopback 100 r1(config-if)#ip vrf forwarding vpn r1(config-if)#ip add 100.1.1.1 255.255.255.255 说明:创建的/32位地址必须放入VRF。 R2: r2(config)#int loopback 100 r2(config-if)#ip vrf forwarding vpn r2(config-if)#ip add 100.1.1.2 255.255.255.255 说明:创建的/32位地址必须放入VRF。 (2)将/32位地址在MP-BGP里发布 R1: r1(config)#router bg 100 r1(config-router)#address-family ipv4 vrf vpn r1(config-router-af)#network 100.1.1.1 mask 255.255.255.255 R2: r2(config)#router bg 100 r2(config-router)#address-family ipv4 vrf vpn r2(config-router-af)#network 100.1.1.2 mask 255.255.255.255 (3) 创建Sham-Link R1: r1(config)#router ospf 2 vrf vpn r1(config-router)#area 1 sham-link 100.1.1.1 100.1.1.2 cost 10 说明:创建Sham-Link时,要指定源地址和目的地址,并且指明COST值。 R2: r2(config)#router ospf 2 vrf vpn r2(config-router)#area 1 sham-link 100.1.1.2 100.1.1.1 cost 10 说明:创建Sham-Link时,要指定源地址和目的地址,并且指明COST值。 8.查看结果 (1)在PE路由器R1上查看Sham-Link r1#sh ip ospf sham-links Sham Link OSPF_SL0 to address 100.1.1.2 is up Area 1 source address 100.1.1.1 Run as demand circuit DoNotAge LSA allowed. Cost of using 10 State POINT_TO_POINT, Timer intervals configured, Hello 10, Dead 40, Wait 40, Hello due in 00:00:04 Adjacency State FULL (Hello suppressed) Index 2/2, retransmission queue length 0, number of retransmission 0 First 0x0(0)/0x0(0) Next 0x0(0)/0x0(0) Last retransmission scan length is 0, maximum is 0 Last retransmission scan time is 0 msec, maximum is 0 msec r1# 说明:Sham-Link建立成功。 (2)在PE路由器R1上查看MP-BGP的路由 r1#show ip bgp vpnv4 all BGP table version is 21, local router ID is 1.1.1.1 Status codes: s suppressed, d damped, h history, * valid, > best, i - internal, r RIB-failure, S Stale Origin codes: i - IGP, e - EGP, ? - incomplete
Network Next Hop Metric LocPrf Weight Path Route Distinguisher: 100:1 (default for vrf vpn) *> 13.1.1.0/24 0.0.0.0 0 32768 ? r>i24.1.1.0/24 2.2.2.2 0 100 0 ? *> 33.3.3.3/32 13.1.1.3 65 32768 ? * i34.1.1.0/24 2.2.2.2 128 100 0 ? *> 13.1.1.3 128 32768 ? r>i44.4.4.4/32 2.2.2.2 65 100 0 ? *> 100.1.1.1/32 0.0.0.0 0 32768 i *>i100.1.1.2/32 2.2.2.2 0 100 0 i r1# 说明:到达远程场点44.4.4.4的路径选择从MPLS VPN骨干网络中走。 (3)在PE路由器R1上查看VRF的路由 r1#sh ip route vrf vpn Routing Table: vpn Codes: C - connected, S - static, R - RIP, M - mobile, B - BGP D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2 E1 - OSPF external type 1, E2 - OSPF external type 2 i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2 ia - IS-IS inter area, * - candidate default, U - per-user static route o - ODR, P - periodic downloaded static route
Gateway of last resort is not set
34.0.0.0/24 is subnetted, 1 subnets O 34.1.1.0 [110/128] via 13.1.1.3, 00:03:02, Serial1/1 100.0.0.0/32 is subnetted, 2 subnets C 100.1.1.1 is directly connected, Loopback100 B 100.1.1.2 [200/0] via 2.2.2.2, 00:03:19 33.0.0.0/32 is subnetted, 1 subnets O 33.3.3.3 [110/65] via 13.1.1.3, 00:03:02, Serial1/1 24.0.0.0/24 is subnetted, 1 subnets O 24.1.1.0 [110/74] via 2.2.2.2, 00:03:03 13.0.0.0/24 is subnetted, 1 subnets C 13.1.1.0 is directly connected, Serial1/1 44.0.0.0/32 is subnetted, 1 subnets O 44.4.4.4 [110/75] via 2.2.2.2, 00:03:04 r1# 说明:到达远程场点44.4.4.4的路径选择从MPLS VPN骨干网络中走。 注:因为sham-link是要COST值的,相当于物理接口,要调整CE的选路,请调整sham-link和各接口COST值来完成。
外部通信 概述 以上是同一VPN的两个场点之间的通信,因为这两个场点之间RD是一样的,属于同一VPN,所以这样的通信很好实现,被称为内部通信,但是如果不同VPN之间,即不同RD的VPN之间要通信,就要靠配置更多的RT来实现,这样的通信称为外部通信。 以下图为例,在原有两个LAN的基础上,加入LAN 3,原有两个LAN之间的RD为100:1,所以通信没有障碍,但是LAN 3 的RD为100:2,所以需要配置RT允许双方路由的导入导出,才能实现不同LAN的通信。
1.在PE为LAN上创建VRF (1) 在PE R3上创建VRF,并配置不同的RD,为100:2 r3(config)#ip vrf vpn2 r3(config-vrf)#rd 100:2 r3(config-vrf)#route-target both 100:2 r3(config-vrf)#exit r3(config)#int f0/0 r3(config-if)#ip vrf forwarding vpn2 % Interface FastEthernet0/0 IP address 83.1.1.3 removed due to enabling VRF vpn2 r3(config-if)#ip add 83.1.1.3 255.255.255.0 2.配置PE-CE路由协议 说明:配置PE连接LAN 3 的路由协议,在配置PE-CE路由协议时,因为有多个IGP协议可供选择,之前我们已经举例过RIP和OSPF的协议,下面我们再使用EIGRP的PE-CE协议。 (1) 在PE R3上配置EIGRP: r3(config)#router eigrp 1 r3(config-router)#no auto-summary r3(config-router)#address-family ipv4 vrf vpn2 r3(config-router-af)#no auto-summary r3(config-router-af)#network 83.1.1.3 0.0.0.0 r3(config-router-af)#autonomous-system 1 r3(config-router-af)#redistribute bgp 100 metric 10000 100 255 1 1500 说明:在PE上配置EIGRP时,需要在address-family里面再次指定对方邻居的AS号,此AS号为对方正确配置的AS号码,并且将MP-BGP的路由重分布进EIGR。 3.配置EIGRP重分布进BGP (1)在R3上配置EIGRP重分布进BGP: r3(config)#router bgp 100 r3(config-router)#address-family ipv4 vrf vpn2 r3(config-router-af)#redistribute eigrp 1 4.查看MP-BGP中的VRF路由表 r3#sh ip bgp vpnv4 all BGP table version is 25, local router ID is 3.3.3.3 Status codes: s suppressed, d damped, h history, * valid, > best, i - internal, r RIB-failure, S Stale Origin codes: i - IGP, e - EGP, ? - incomplete
Network Next Hop Metric LocPrf Weight Path Route Distinguisher: 100:1 (default for vrf vpn1) *>i10.1.1.0/24 1.1.1.1 1 100 0 ? *>i14.1.1.0/24 1.1.1.1 0 100 0 ? *> 36.1.1.0/24 0.0.0.0 0 32768 ? *> 192.168.1.6/32 36.1.1.6 65 32768 ? Route Distinguisher: 100:2 (default for vrf vpn2) *> 83.1.1.0/24 0.0.0.0 0 32768 ? *> 172.16.1.0/24 83.1.1.8 409600 32768 ? r3# 说明:从VRF表中可以看出,LAN 3 的VRF和其它两个LAN的VRF并不同步,所以不可能实现通信。 5.配置RT允许双方VRF进入 说明:因为双方VRF的允许的RD不一样,所以路由表无法彼此进入,因此可以配置RT允许相互进出。 (1) 在PE R3上配置RT同时允许双方RD: r3(config)#ip vrf vpn1 r3(config-vrf)#route-target both 100:2
r3(config)#ip vrf vpn2 r3(config-vrf)#route-target both 100:1
(2)在PE R1上配置RT同时允许双方RD: r1(config)#ip vrf vpn1 r1(config-vrf)#route-target both 100:2 6.查看双方VRF路由表 说明:因为RT已经允许双方路由进出相互的VRF,所以双方VRF路由表中应该有相互的路由信息。 (1) 在R3上查看MP-BGP VRF路由表: r3#sh ip bgp vpnv4 all BGP table version is 37, local router ID is 3.3.3.3 Status codes: s suppressed, d damped, h history, * valid, > best, i - internal, r RIB-failure, S Stale Origin codes: i - IGP, e - EGP, ? - incomplete
Network Next Hop Metric LocPrf Weight Path Route Distinguisher: 100:1 (default for vrf vpn1) *>i10.1.1.0/24 1.1.1.1 1 100 0 ? *>i14.1.1.0/24 1.1.1.1 0 100 0 ? *> 36.1.1.0/24 0.0.0.0 0 32768 ? *> 83.1.1.0/24 0.0.0.0 0 32768 ? *> 172.16.1.0/24 83.1.1.8 409600 32768 ? *> 192.168.1.6/32 36.1.1.6 65 32768 ? Route Distinguisher: 100:2 (default for vrf vpn2) *>i10.1.1.0/24 1.1.1.1 1 100 0 ? *>i14.1.1.0/24 1.1.1.1 0 100 0 ? *> 36.1.1.0/24 0.0.0.0 0 32768 ? *> 83.1.1.0/24 0.0.0.0 0 32768 ? *> 172.16.1.0/24 83.1.1.8 409600 32768 ? *> 192.168.1.6/32 36.1.1.6 65 32768 ? r3# 说明:双方的VRF已经同步。 (2)在CE R4上查看路由表: r4#sh ip route Codes: C - connected, S - static, R - RIP, M - mobile, B - BGP D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2 E1 - OSPF external type 1, E2 - OSPF external type 2 i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2 ia - IS-IS inter area, * - candidate default, U - per-user static route o - ODR, P - periodic downloaded static route
Gateway of last resort is not set
83.0.0.0/24 is subnetted, 1 subnets R 83.1.1.0 [120/1] via 14.1.1.1, 00:00:19, Serial1/1 36.0.0.0/24 is subnetted, 1 subnets R 36.1.1.0 [120/1] via 14.1.1.1, 00:00:19, Serial1/1 172.16.0.0/24 is subnetted, 1 subnets R 172.16.1.0 [120/1] via 14.1.1.1, 00:00:19, Serial1/1 10.0.0.0/24 is subnetted, 1 subnets C 10.1.1.0 is directly connected, Serial1/0 192.168.1.0/32 is subnetted, 1 subnets R 192.168.1.6 [120/1] via 14.1.1.1, 00:00:19, Serial1/1 14.0.0.0/24 is subnetted, 1 subnets C 14.1.1.0 is directly connected, Serial1/1 r4# 说明:双方的VRF已经同步。 7.测试两个LAN的连通性 说明:因为双方的VRF路由表已经相同,所以应该可以通信 (1)在CE路由器R5上测试到LAN3 172.16.1.8的连通性: R5ping r5#ping 172.16.1.8
Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 172.16.1.8, timeout is 2 seconds: !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 188/241/340 ms r5# 说明:成功实现不同LAN之间的外部通信。 点此查看配置实例所有设备的 show running-config CE接入英特网 概述
如上图所示,PE路由器R1与Internet核心路由器Core相连,因为PE路由器R1连CE路由器R4的接口已经被划入VRF vpn1中,所以从CE R4过来的数据包,PE都是根据VRF vpn1的路由表来作出转发决定的,当CE要将数据包发往Internet的时候,PE是不会转发的,因为在VRF vpn1中,除了对方LAN的路由信息之外,并无到Internet核心的路由,所以要让CE到Internet核心的数据包被PE转发,那么就必须在PE上为VRF vpn1配置到Internet的路由,这样,CE才能直接访问Internet。 除了在VRF中静态为CE添加路由之外,还有一种方法就是,在PE和CE之间额外创建tunnel,当CE到Internet的数据包发往Tunnel时,PE就将该数据包发往Internet。 最后一种让CE能够访问Internet的方法就是,CE将自己的路由发往对端LAN,让对端的LAN作转发处理。
配置 1.配置VRF静态路由 说明:直接为用户的VRF写到Internet的默认路由,让CE的VRF拥有到Internet的默认路由之后,就可以访问Internet。 (1)在PE上为VRF配置默认路由: r1(config)#ip route vrf vpn1 0.0.0.0 0.0.0.0 100.1.1.2 global 说明:为VRF vpn1添加默认路由指向下一跳100.1.1.2 (2)在PE上还需手工指定到CE内部网络的路由: r1(config)#ip route 10.1.1.0 255.255.255.0 serial 1/1 14.1.1.4 (3)最后CE上也要写默认路由到PE: R4(config)#ip route 0.0.0.0 0.0.0.0 14.1.1.1 (4)测试CE到Internet核心的连通性: r5#ping 100.1.1.2
Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 100.1.1.2, timeout is 2 seconds: !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 188/241/340 ms r5# 说明:CE到Internet核心的通信正常。 2.在PE-CE间配置Tunnel (1)在PE上配置到CE和Tunnel: r1(config)#int tunnel 0 r1(config-if)#ip address 50.1.1.1 255.255.255.0 r1(config-if)#tunnel source 14.1.1.1 r1(config-if)#tunnel destination 14.1.1.4 r1(config-if)#tunnel vrf vpn1 r1(config-if)#exit 说明:配置了到CE的Tunnel之后,还必须将该Tunnel放到VRF中。 (2)配置到CE内部网络的路由都走tunnel: r1(config)#ip route 10.1.1.0 255.255.255.0 tunnel 0 (3)在CE上配置到PE的tunnel: r4(config)#int tunnel 0 r4(config-if)#ip address 50.1.1.4 255.255.255.0 r4(config-if)#tunnel source 14.1.1.4 r4(config-if)#tunnel destination 14.1.1.1 r4(config-if)#exit (4)指定CE所有的路由都从Tunnel发给PE: r4(config)#ip route 0.0.0.0 0.0.0.0 tunnel 0 (5)测试CE到Internet核心的连通性: r5#ping 100.1.1.2
第三种方法将所有数据发到自己核心总部再转出去,略。 更多PE-CE路由协议 说明:之前说过PE-CE的路由协议有多种,我们已经举例过RIP,OSPF,EIGRP,下面来举例静态写VRF,还有就是EBGP。 1.静态写VRF路由 说明:PE的VRF中如果没有到CE的内部路由,将无法为不同LAN之间提供数据包转发,所以PE必须获得CE的内部网络路由信息,可以使用动态路由协议,也可以静态写VRF路由。 (1)在PE R1上写静态的VRF路由指向CE: r1(config)#ip route vrf vpn1 10.1.1.0 255.255.255.0 14.1.1.4 (2)在PE R3上写静态的VRF路由指向CE: r3(config)#ip route vrf vpn1 192.168.1.0 255.255.255.0 36.1.1.6 (3)在PE R1上将静态路由重分布进MP-BGP: 说明:PE上的VRF中已经拥有到CE内部网络的路由后,如果这个信息不发给远程LAN,那么双方LAN之间也不能通信,所以可以将此静态路由重分布进MP-BGP,从而发给远程LAN。 r1(config)#router bgp 100 r1(config-router)#address-family ipv4 vrf vpn1 r1(config-router-af)#redistribute static r1(config-router-af)#exi (4)在PE R3上将静态路由重分布进MP-BGP: r3(config)#router bgp 100 r3(config-router)#address-family ipv4 vrf vpn1 r3(config-router-af)#redistribute static (5)CE R4也要写默认路由指向PE: r4(config)#ip route 0.0.0.0 0.0.0.0 14.1.1.1 (6)CE R6也要写默认路由指向PE: r6(config)#ip route 0.0.0.0 0.0.0.0 36.1.1.3 (7)测试双方LAN的连通性: r5#ping 192.168.1.6
Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 192.168.1.6, timeout is 2 seconds: !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 148/236/320 ms r5# 说明:通过PE和CE之间写静态路由,双方LAN之间通信正常。 2.PE-CE之间运行EBGP 说明:PE和CE之间只能运行EBGP,因为当PE学到CE的路由后,要发给远程LAN,所以此路由需要导入MP-BGP,但是这种重分布在EBGP和MP-BGP之间会自动执行,无需额外配置。 (1)在PE R1上配置到CE的EBGP: r1(config)#router bg 100 r1(config-router)#address-family ipv4 vrf vpn1 r1(config-router-af)#neighbor 14.1.1.4 remote-as 200 r1(config-router-af)#neighbor 14.1.1.4 activate (2)在PE R3上配置到CE的EBGP: r3(config)#router bgp 100 r3(config-router)#address-family ipv4 vrf vpn1 r3(config-router-af)#neighbor 36.1.1.6 remote-as 300 r3(config-router-af)#neighbor 36.1.1.6 activate r3(config-router-af)# (3)在CE R4上配置到PE的EBGP: r4(config)#router bgp 200 r4(config-router)#neighbor 14.1.1.1 remote r4(config-router)#neighbor 14.1.1.1 remote-as 100 r4(config-router)#network 10.1.1.0 mask 255.255.255.0 (4)在CE R6上配置到PE的EBGP: r6(config)#router bgp 200 r6(config-router)#neighbor 36.1.1.3 remote-as 100 r6(config-router)#network 192.168.1.0 mask 255.255.255.0 (5)解决BGP路由问题: 说明:因为在LAN1和LAN2之间配置的BGP AS号码都为200,而本端BGP在收到路由时,如果发现路由携带的AS和自己的AS相同,则丢弃该路由,所以双方的CE都不会有对方的路由,所以这个问题要在PE的BGP上配置允许AS重叠。
r1(config)#router bgp 100 r1(config-router)#address-family ipv4 vrf vpn1 r1(config-router-af)#neighbor 14.1.1.4 as-override
r3(config)#router bgp 100 r3(config-router)#address-family ipv4 vrf vpn1 r3(config-router-af)#neighbor 36.1.1.6 as-override
(6)测试连通性: r5#ping 192.168.1.6
Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 192.168.1.6, timeout is 2 seconds: !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 148/236/320 ms r5# 说明:通过PE上额外的配置,CE之间的BGP AS号码重叠问题被解决,双方LAN之间实现通信。
Multi-VRF CE / VRF-Lite 概述 当在PE上将连接CE的接口放入VRF表之后,那么从此接口过来的所有CE数据都属于该VRF,都根据该VRF来做出转发决定,所以从同一个接口发来的用户数据,都执行相同的路由查询。 如果一个很大的公司,这个公司有两个分公司通过Internet相连,并且每个分公司都存在多个部门,那么当在正常实施MPLS_VPN时,要么让两个公公司的所有部门都能通信,因为他们走的是同一个VRF路由表,要么都不能通信。 当某些时候因为业务要求,如果要让两个分公司的不同部门之间不能通信,按照MPLS_VPN的理论,就应该为要通信的部门单独创建VRF,再为不要通信的部门之间单独创建VRF,只有这样,才能将不同部门的数据隔离开来。 正因为CE连到PE的接口所有数据都属于同一个VRF,所以当CE和PE之间只有一根链路相连时,要创建多个VRF,这是不能实现的。但是,如果PE和CE之间是以太网链路,是可以支持子接口划分的,也就是可以通过为子接口划分不同的VLAN来实现。除了子接口之外,最好的办法就是在PE和CE间拉多条线路。 如果只通过在PE上将不同链路划入不同的VRF,也可以达到隔离部门的需求。但是还有个方法就是,还可以直接在CE上面就将连接不同部门的接口直接划入不同的VRF。因为在平时,要将接口划入VRF,是在PE上做的,而CE是不了解VRF的,也就是说MPLS_VPN对于CE端来说是透明的,那么现在要让CE也能够认识VRF,能够成功为不同接口划不同的VRF,这就需要扩展CE具有PE的功能,这种功能被称为Multi-VRF CE 或VRF-Lite,在CE上为不同接口划VRF的同时,PE上的VRF将继续保留不可删除,所以PE的功能将不作变动。而在CE将路由传递给PE时,这中间运行的协议是OSPF,并且还要扩展OSPF的 vrf-lite功能。 下面以下图为例,来详细讲解VRF-Lite的配置
说明:红色部分网络为需要通信的部门,但和蓝色网络的部门作隔离,其中R1、R2、R3上均已配置loopback0,地址分别为1.1.1.1/32,2.2.2.2/32,3.3.3.3/32,并且已经配置好OSPF,让MPLS区域内所有直连接口和loopback口互通。下面以配置红色网络部门通信为例,蓝色网络部门通信与红色部门相似,请自行参考配置。 1.将MPLS区域网络配通 说明:此步略过,详细步骤请参见之前部分。 2.配置MP-BGP 说明:配置R1和R3之间的MP-BGP (1) 在R1上配置MP-BGP: r1(config)#router bgp 100 r1(config-router)#neighbor 3.3.3.3 remote-as 100 r1(config-router)#neighbor 3.3.3.3 update-source loopback 0 r1(config-router)#address-family vpnv4 r1(config-router-af)#neighbor 3.3.3.3 activate r1(config-router-af)#neighbor 3.3.3.3 send-community both (2)在R1上配置MP-BGP: r3(config)#router bgp 100 r3(config-router)#neighbor 1.1.1.1 remote-as 100 r3(config-router)#neighbor 1.1.1.1 update-source loopback 0 r3(config-router)#address-family vpnv4 r3(config-router-af)#neighbor 1.1.1.1 activate r3(config-router-af)#neighbor 1.1.1.1 send-community both 3.在CE上为不同部门创建不同VRF 说明:在CE上为不同部门创建不同VRF,并配置好RD和RT (1)在R4上为相应接口创建VRF: r4(config)#ip vrf vpn1 r4(config-vrf)#rd 100:1 r4(config-vrf)#route-target both 100:1 (2)在R5上为相应接口创建VRF: r5(config)#ip vrf vpn1 r5(config-vrf)#rd 100:1 r5(config-vrf)#route-target both 100:1 4.将相应部门的接口划入相应VRF (1) 在R4上将相应接口划入相应VRF: r4(config)#int loopback 10 r4(config-if)#ip vrf forwarding vpn1 r4(config-if)#ip add 10.1.1.1 255.255.255.0
r4(config)#int f0/0 r4(config-if)#ip vrf forwarding vpn1 r4(config-if)#ip add 30.1.1.4 255.255.255.0
(2)在R5上将相应接口划入相应VRF: r5(config)#int loopback 172 r5(config-if)#ip vrf forwarding vpn1 r5(config-if)#ip add 172.16.1.1 255.255.255.0
r5(config)#int f0/0 r5(config-if)#ip vrf forwarding vpn1 r5(config-if)#ip add 50.1.1.5 255.255.255.0 5.配置PE-CE间的OSPF (1) 在CE R4上启动OSPF,并将相应路由放进OSPF进程,传送给PE: r4(config)#router ospf 100 vrf vpn1 r4(config-router)#capability vrf-lite r4(config-router)#network 10.1.1.1 0.0.0.0 a 0 r4(config-router)#network 30.1.1.4 0.0.0.0 a 0 注:命令capability vrf-lite为扩展OSPF,必须输入,否则OSPF无法接收路由。 (2)在CE R5上启动OSPF,并将相应路由放进OSPF进程,传送给PE: r5(config)#router ospf 100 vrf vpn1 r5(config-router)#capability vrf-lite r5(config-router)#network 172.16.1.1 0.0.0.0 a 0 r5(config-router)#network 50.1.1.5 0.0.0.0 a 0 注:命令capability vrf-lite为扩展OSPF,必须输入,否则OSPF无法接收路由。 6.在PE上创建VRF (1)在PE R1上为CE的不同部门也创建不同的VRF,并将连CE的相应线路划入相应VRF: r1(config)#ip vrf vpn1 r1(config-vrf)#rd 100:1 r1(config-vrf)#route-target both 100:1
r1(config)#int f0/0 r1(config-if)#ip vrf forwarding vpn1 r1(config-if)#ip add 30.1.1.1 255.255.255.0 (2)在PE R3上为CE的不同部门也创建不同的VRF,并将连CE的相应线路划入相应VRF: r3(config)#ip vrf vpn1 r3(config-vrf)#rd 100:1 r3(config-vrf)#route-target both 100:1
r3(config)#int f0/0 r3(config-if)#ip vrf forwarding vpn1 r3(config-if)#ip add 50.1.1.3 255.255.255.0 7.在PE上启动OSPF (1)在PE R1上也启用OSPF,用来接收CE发来的各部门的路由,以便让这些部门相通: r1(config)#router ospf 100 vrf vpn1 r1(config-router)#network 30.1.1.1 0.0.0.0 a 0 (2)在PE R1上也启用OSPF,用来接收CE发来的各部门的路由,以便让这些部门相通: r3(config)#router ospf 100 vrf vpn1 r3(config-router)#network 50.1.1.3 0.0.0.0 a 0 8.在MP-BGP和OSPF间重分布 说明:将MP-BGP和OSPF相互重分布,最终让相应部门实现通信。 (1) 在PE R1上做MP-BGP和OSPF的双向重分布: r1(config)#router ospf 100 vrf vpn1 r1(config-router)#redistribute bgp 100 subnets
r1(config)#router bgp 100 r1(config-router)#address-family ipv4 vrf vpn1 r1(config-router-af)#redistribute ospf 100 vrf vpn1
(2)在PE R3上做MP-BGP和OSPF的双向重分布: r3(config)#router ospf 100 vrf vpn1 r3(config-router)#redistribute bgp 100 subnets
r3(config)#router bgp 100 r3(config-router)#address-family ipv4 vrf vpn1 r3(config-router-af)#redistribute ospf 100 vrf vpn1 9.查看CE各自VRF的路由 (1)在CE R4上查看VRF vpn1的路由: r4#sh ip route vrf vpn1
Routing Table: vpn1 Codes: C - connected, S - static, R - RIP, M - mobile, B - BGP D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2 E1 - OSPF external type 1, E2 - OSPF external type 2 i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2 ia - IS-IS inter area, * - candidate default, U - per-user static route o - ODR, P - periodic downloaded static route
Gateway of last resort is not set
50.0.0.0/24 is subnetted, 1 subnets O IA 50.1.1.0 [110/11] via 30.1.1.1, 00:06:00, FastEthernet0/0 172.16.0.0/24 is subnetted, 1 subnets O IA 172.16.1.0 [110/21] via 30.1.1.1, 00:06:00, FastEthernet0/0 10.0.0.0/24 is subnetted, 1 subnets C 10.1.1.0 is directly connected, Loopback10 30.0.0.0/24 is subnetted, 1 subnets C 30.1.1.0 is directly connected, FastEthernet0/0 r4# 说明:CE R4的VRF vpn1已经拥有双方部门的路由,应该可以实现部门间通信。
(2)在CE R5上查看VRF vpn1的路由: r5#sh ip route vrf vpn1
Routing Table: vpn1 Codes: C - connected, S - static, R - RIP, M - mobile, B - BGP D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2 E1 - OSPF external type 1, E2 - OSPF external type 2 i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2 ia - IS-IS inter area, * - candidate default, U - per-user static route o - ODR, P - periodic downloaded static route
Gateway of last resort is not set
50.0.0.0/24 is subnetted, 1 subnets C 50.1.1.0 is directly connected, FastEthernet0/0 172.16.0.0/24 is subnetted, 1 subnets C 172.16.1.0 is directly connected, Loopback172 10.0.0.0/24 is subnetted, 1 subnets O IA 10.1.1.0 [110/21] via 50.1.1.3, 00:05:07, FastEthernet0/0 30.0.0.0/24 is subnetted, 1 subnets O IA 30.1.1.0 [110/11] via 50.1.1.3, 00:05:07, FastEthernet0/0 r5# 说明:CE R4的VRF vpn1已经拥有双方部门的路由,应该可以实现部门间通信。 10.测试连通性 说明:双方CE在相应VRF都拥有双方部门的路由信息,因此可以实现部门间通信。 (1)在CE R4上ping远程部门地址做测试: 说明:在上图中,测试时,因为数据从CE发出,默认不是走VRF表,所以发送ICMP时,除了指定源地址外,还要指定数据走相应的VRF路由表,否则测试不正确。 r4#ping vrf vpn1 172.16.1.1 source loopback 10
Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 172.16.1.1, timeout is 2 seconds: Packet sent with a source address of 10.1.1.1 !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 96/116/164 ms r4# 说明:通过配置VRF Lite,实现了远程公司之间的部门通信,而不在同一VRF的不同部门,通信将被隔离。 点此查看配置实例所有设备的 show running-config 以上配置实例为红色网络部门间的通信,只要配置蓝色部门为不同的VRF和不同的RD,通信将可实现隔离功能,蓝色网络的通信,请自行参照红色网络的配置。
注:本人能力有限,如遇不足之处,还请指正! |
||
China-CCIE QQ交流群:106155045
|